Installation Result
Message: The update completed successfully, but the system needs to be rebooted for the changes to be effective.
Reboot Required: true
VIBs Installed: Avago_bootbank_scsi-mpt2sas_20.00.01.00-1OEM.550.0.0.1331820
VIBs Removed: VMW_bootbank_scsi-mpt2sas_19.00.00.00-2vmw.670.0.0.8169922
VIBs Skipped:
安装好,重启后,使用./lsiutil来变更writecache设置
LSI Logic MPT Configuration Utility, Version 1.71, Sep 18, 2013
sh: /sbin/modprobe: not found
mknod: /dev/mptctl: Function not implemented
1 MPT Port found
Port Name Chip Vendor/Type/Rev MPT Rev Firmware Rev IOC
1. ioc0 LSI Logic SAS2308 D1 200 14000700 0
# 输入21,选择RAID 操作
21. RAID actions
# 输入32,选择变更RAID设置
RAID actions menu, select an option: [1-99 or e/p/w or 0 to quit] 32
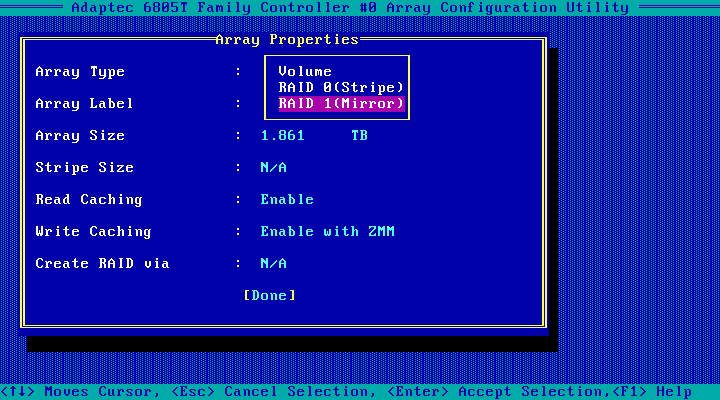
Volume 0 is DevHandle 011d, Bus 1 Target 1, Type RAID1 (Mirroring)
Volume 1 is DevHandle 011e, Bus 1 Target 0, Type RAID1 (Mirroring)
# 输入0,选择对应RAID盘
Volume: [0-1 or RETURN to quit] 0
Volume 0 Settings: write caching enabled, auto configure hot swap enabled
Volume 0 draws from Hot Spare Pools: 0
Write caching: [0=Disabled, 1=Enabled, 2=MemberControlled, default is 1]
# 输入1,打开Write Cache!
I0721 03:54:55.082767 1 match.go:206] Determining IP address of default interface
I0721 03:54:55.083292 1 match.go:259] Using interface with name ens192 and address 10.0.0.39
I0721 03:54:55.083350 1 match.go:281] Defaulting external address to interface address (10.0.0.39)
I0721 03:54:55.083485 1 vxlan.go:138] VXLAN config: VNI=1 Port=0 GBP=false Learning=false DirectRouting=false
E0721 03:54:55.084170 1 main.go:330] Error registering network: failed to acquire lease: node "fed-k8s-master" pod
cidr not assigned
I0721 03:54:55.084272 1 main.go:447] Stopping shutdownHandler...
W0721 03:54:55.084438 1 reflector.go:436] github.com/flannel-io/flannel/subnet/kube/kube.go:403: watch of *v1.Node
ended with: an error on the server ("unable to decode an event from the watch stream: context canceled") has prevented
the request from succeeding
我脑子抽了就直接用SD卡里的Ubuntu shell 直接 dd if=/dev/zero of=/dev/nvme0n1 …… 想通过干掉分区表(GPT)来阻止从nvme启动。结果噩梦就开始了,SD卡里的Ubuntu怎么都找不到nvme和U盘了。折腾了一晚没啥收获,第二天不停的重启和对比才发现。UBoot启动的过程中需要启动pci!要不然你怎么执行命令启动USB都是不行的,usb start 就会报错 no working controllers found