最近攒了台DL20Gen9垃圾服务器,准备做成All-in-one(路由、NAS、监控)。
为了节省磁盘的电,就买了2块硬盘的版本。
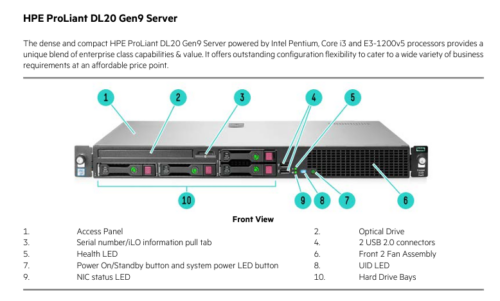

配置清单:
- 某宝淘的准系统 (¥700)
- Intel(R) Xeon(R) CPU E3-1270 v5 @ 3.60GHz (¥113)
- 4 x 16GB 2133 ECC Unbuffered 三星内存 (¥600)
- 2 x 12 TB 氦气盘 (¥1180)
- 256G 长城nvme (¥113)
- HP Ethernet 10Gb 2-port 560SFP+ Adapter (¥99)
总记:¥2777
坑
- DL20gen9 支持最大64G 2133/2400 ECC内存(Unbuffered,某宝上一般叫纯ECC,别买错了)。
- 想用最大的内存,2133只能配v5的CPU,2400只能配v6,如果混着了,就只能识别一半出来。
- 如果你买到了坏的CPU,可能会出现DIMM cann't train的错误提示(我就因此换了所有硬件,最后只能是归到CPU上了)
- 各种固件需要自己更新,要不然一些v5的CPU是无法识别的。
方便链接
iLo4 更新,主要是为了HTML5 的remote console
https://pingtool.org/latest-hp-ilo-firmwares/
System ROM(BIOS)
https://www.chiphell.com/forum.php?mod=viewthread&tid=2643119&extra=page%3D1&ordertype=2&mobile=no
HP这iLo还要许可证,坑爹到家了,贴一个在这了。
iLO 4 高级许可证密钥:
35DPH-SVSXJ-HGBJN-C7N5R-2SS4W
35SCR-RYLML-CBK7N-TD3B9-GGBW2