开篇前言
Go项目在发展过程中有过许许多多的bug,核心开发组在解决bug的时候有各种各样的方法,涉及的知识点都很值得学习。
我觉得这些都挺值得跟大家分享,也希望做成一个不鸽系列。
正题
Issue地址:issues/35541
开发:Cherry Zhang, Michael Knyszek
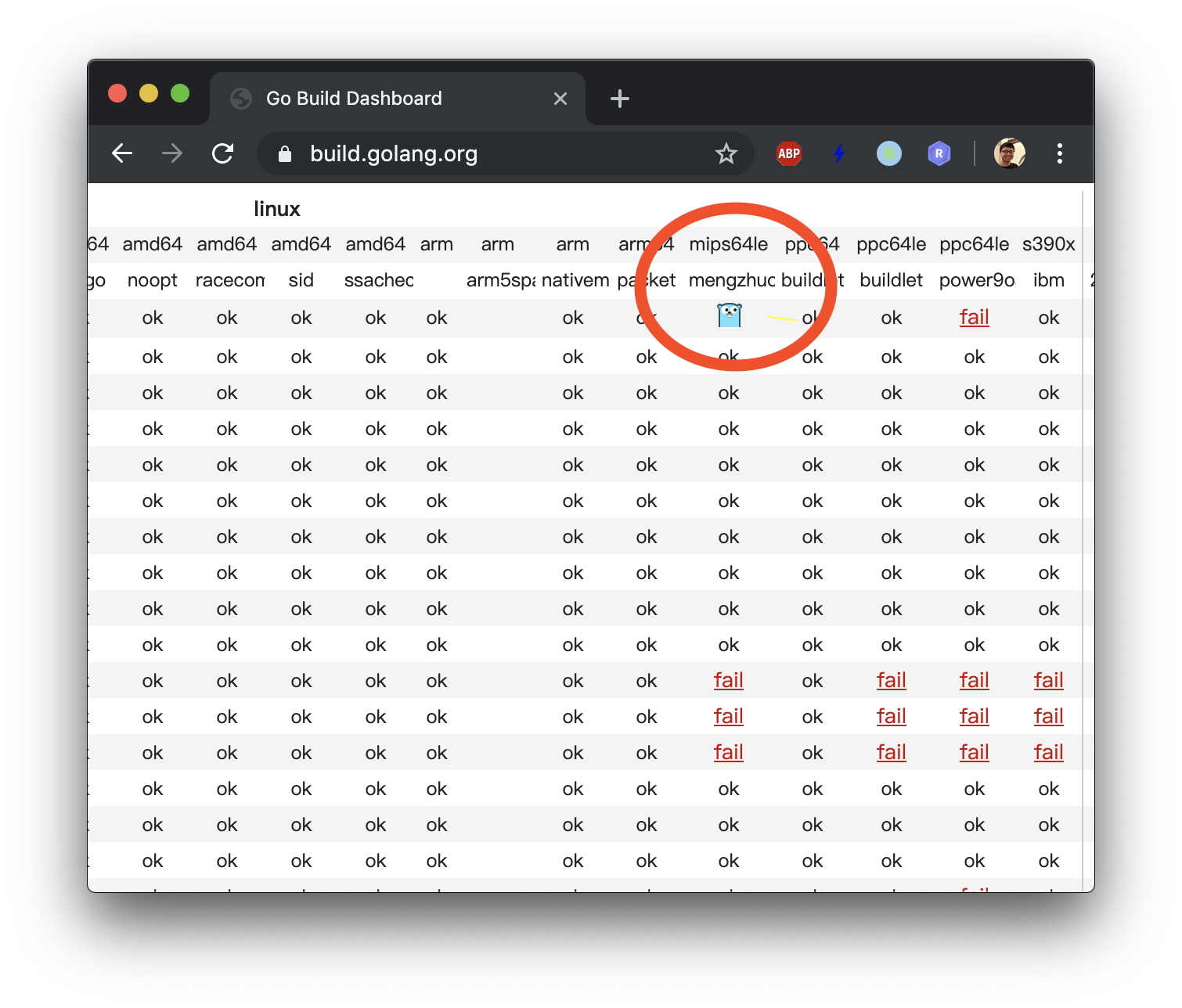
这个bug是由Go的自动构建机器linux-mipsle-mengzhuo在日常测试过程中首次发现的,
表现是某个对象里的指针指向了一个不存在的span上,导致runtime panic。
Cherry根据 经验 判断出这个span类型是goroutine用的,并且贴出了对应的对象映射(如下)
object=0xc000106300 s.base()=0xc000106000 s.limit=0xc000107f80 s.spanclass=42 s.elemsize=384 s.state=mSpanInUse
*(object+0) = 0xc00052a000 g.stack.lo
*(object+8) = 0xc000532000 g.stack.hi
*(object+16) = 0xc00052a380 g.stackguard0 = g.stack.lo + _Stackguard = g.stack.lo + 896
*(object+24) = 0xffffffffffffffff g.stackguard1
*(object+32) = 0x0 g._panic
*(object+40) = 0xc0005313e0 <== // 故障点 g._defer
*(object+48) = 0xc000080380 g.m
*(object+56) = 0xc0005310b8 g.sched.sp
*(object+64) = 0x87038 g.sched.pc
*(object+72) = 0xc000106300 g.sched.g
虽然Cherry没有明说如何判断出是goroutine,但其中的偏移量24字节处的数据正好是64位的满位,
看起来确实像一般的goroutine的stackguard1 (malg时分配的)
这个bug奇怪的地方在于不是必现,是在不同的函数,时不时runtime panic, 而且出问题的span有时是在用的,有时又是废弃的。
更奇怪的是,RTRK(塞尔维亚的一家科研机构)提供的MIPS构建机从来都没有出现过一次类似原因的runtime panic。
一开始,开发组认为是MIPS的问题,时间长了,发现还有plan9-arm,
darwin-arm64-corellium这两个架构也出现了类似问题,然而出现的频率远不如MIPS高。
因为没有有效解,几乎每周Bryan Mills(负责Go开发质量的工程师)都会在Github Issue中填上新增的panic日志地址,最后他也嫌烦了……
脑袋疼.jpg
问题定位
事情的转机是我有一次debug过程中,发现runtime有个测试函数TestDeferHeapAndStack 总是 会引发这个panic。
而在Go项目的自动化整体测试中,为了测试尽快完成,通常速度慢的机器都会选择short mode,
而恰好这个short mode不会导致panic。
本身这个测试也很有意思,因为编译器只会把函数作用域中无指针的defer分配在stack上,而循环体中的defer就会分配在heap中。
测试用例如下:
func deferHeapAndStack(n int) (r int) {
if n == 0 {
return 0
}
if n%2 == 0 {
// heap-allocated defers
for i := 0; i < 2; i++ {
defer func() {
r++
}()
}
} else {
// stack-allocated defers
defer func() {
r++
}()
defer func() {
r++
}()
}
r = deferHeapAndStack(n - 1)
escapeMe(new([1024]byte)) // force some GCs
return
}
我尝试着自己修复这个bug,然而失败了,不过既然可以稳定重现,那可以帮助核心团队来bisect这个bug。
这个技能是从Austin(Go runtime leader)学来的(他如何从Go定位Linux bug正好可以写下一期哈)。
因为这个bug是从1.13之后才有的,所以我选择了HEAD 和 go1.13.9之间开始定位。
$ git bisect HEAD go1.13.9
$ git bisect run ./test.sh // 就是跑上面deferTest的脚本
最后发现是runtime: rearrange mheap_.alloc* into allocSpan这个commit导致了bug。
修复方法
Cherry在和Michael聊这个bug之后发现在allocSpan的过程中由于缺了一个内存屏障(memory barrier),
在弱内存顺序模型的机器上这个bug会随机出现。以下是她的修复commit:
When copying a stack, we
1. allocate a new stack,
2. adjust pointers pointing to the old stack to pointing to the
new stack.
If the GC is running on another thread concurrently, on a machine
with weak memory model, the GC could observe the adjusted pointer
(e.g. through gp._defer which could be a special heap-to-stack
pointer), but not observe the publish of the new stack span. In
this case, the GC will see the adjusted pointer pointing to an
unallocated span, and throw. Fixing this by adding a publication
barrier between the allocation of the span and adjusting pointers.
One testcase for this is TestDeferHeapAndStack in long mode. It
fails reliably on linux-mips64le-mengzhuo builder without the fix,
and passes reliably after the fix.
简单翻译一下:
当拷贝一个栈数据(stack)时,我们先:
1. 申请一个新的栈空间
2. 将老的栈上的指针(pointer)从老栈指向新栈上。
如果此时在另一个线程并行地执行着GC(垃圾回收),且架构是弱内存顺序模型时,GC可以观察到指针的调整
(例如: gp._defer 就是一个特殊的 heap-to-stack 指针),但是观察不到新的栈分配。
这时GC就会观察到指针分配到了一个没有分配的空间中。
我们通过在分配和调整指针之间添加内存屏障(memory barrier)来修复这个bug。
代码就更简单了,只是在allocSpan的过程中添加了一个函数publicationBarrier()。
什么是内存顺序模型可以参考这个系列的文章《Memory Barriers Are Like Source Control Operations》。
X86没有问题,是因为强内存模型保证了每个写入操作的顺序能在各个CPU之间保证同步。
而弱内存模型就没有保证这点,所以强制sync
等等,你问为啥ARM没有这个问题?这是玄学(划掉
因为ARM虽然是弱内存模型,但是保证了“Data dependency barrires”
所以以后碰到诡异的多线程问题,就先sync(手动狗头
那么什么是内存顺序模型?
咕咕咕……回头再补
多线程问题
MESI
小结
参考资料
[^1] https://blog.golang.org/ismmkeynote
[^2] https://www.ardanlabs.com/blog/2018/12/garbage-collection-in-go-part1-semantics.html
[^3] https://zhuanlan.zhihu.com/p/48157076