最近小黄鱼买了台二手的麒麟 9000C 信创台式机(华为擎云 W515X),预装 Kylin V10 SP1。最大的问题是软件源老旧、内核锁死 5.10,我想要一个现代化的 Debian 开发环境,所以就开始了折腾。
为什么
Kylin V10 SP1 基于 Ubuntu 20.04 时代的软件栈,gcc 9.4、python 3.8,想用点新东西处处受限。但这台机器有几个硬约束:
- 内核是华为定制 5.10.97-23-9000c,换不了(主线没有麒麟 9000C 的任何支持,显示/GPU/WiFi 全靠厂商驱动)
- 不能影响原系统(还要正常办公用)
所以路线很清晰:厂商内核不动,用户态整个换成 Debian 13 (trixie)。类似 Android 上的 Linux Deploy、WSL1 的思路 —— chroot/容器共享宿主机内核,零虚拟化开销。
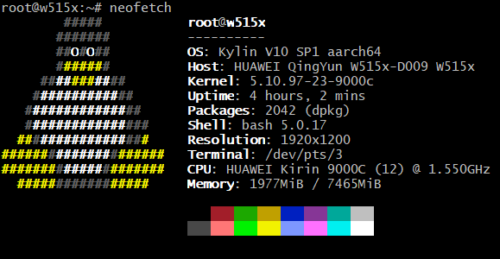
最终效果:
$ ssh root@10.0.0.127 # 一台"独立"的 Debian 机器
root@w515x:~# cat /etc/os-release | grep PRETTY
PRETTY_NAME="Debian GNU/Linux 13 (trixie)"
root@w515x:~# systemctl is-system-running
running # 完整 systemd,不是阉割版 chroot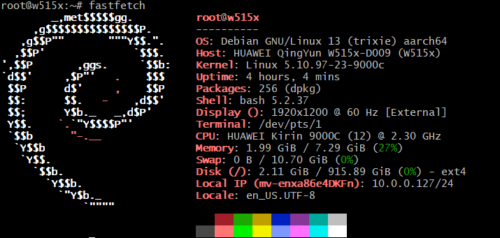
独立 IP(10.0.0.127,和宿主机的 10.0.0.247 互不干扰)、完整 systemd、原生性能、apt 源直连国内镜像。
第一次尝试:debootstrap 构建 rootfs
容器载体是机器上那块 1TB 数据盘(/media/user/DATA1,ext4)。理论上就是一条命令:
debootstrap --arch=arm64 --variant=minbase trixie /media/user/DATA1/debian-arm64 \
http://mirrors.ustc.edu.cn/debian然后连续踩了三个坑。
坑 1:udisks 挂载选项
数据盘是桌面环境 udisks 自动挂载的,默认 nosuid,nodev —— 而 debootstrap 要在目标里创建设备节点、将来 chroot 里 sudo/su 也需要 suid。直接报 Cannot install into target ... mounted with noexec or nodev。
mount -o remount,suid,dev /media/user/DATA1(根治方案见后面 fstab 那步。)
坑 2:kysec 执行控制
Kylin 自带的安全模块 kysec 会拦截"非系统路径"的程序执行。debootstrap 做 test-exec 时直接 Permission denied,就算构建完了,chroot 里任何程序也跑不起来(解释器错误: 权限不够)。
setstatus -f exectl -p off # 关闭执行控制(重启失效)getstatus 可以查看状态。这是信创系统特有的"惊喜",文档里基本查不到。
坑 3:Kylin 的 debootstrap 太老
Kylin 仓库里的 debootstrap 是 1.0.118 魔改版,跑 trixie 会在提取 base-files 后报:
E: Tried to extract package, but file already exists. Exit...原因是 Debian 12+ 全面转向 merged-usr(/bin、/sbin 是到 /usr 的符号链接),老 debootstrap 处理不了这种包布局。而且 trixie 的 suite 脚本它都没有(得自己 ln -sf sid trixie)。
解决办法就是从另一台机器拷一份新版 debootstrap(纯 shell 脚本,无依赖),例如:
# 在有 Debian 13 的机器上:
tar czf - -C / usr/sbin/debootstrap usr/share/debootstrap | \
ssh root@10.0.0.247 'mkdir -p /tmp/d141 && tar xzf - -C /tmp/d141'
# 在 Kylin 上运行新版:
DEBOOTSTRAP_DIR=/tmp/d141/usr/share/debootstrap \
/tmp/d141/usr/sbin/debootstrap --arch=arm64 --variant=minbase \
trixie /media/user/DATA1/debian-arm64 http://mirrors.ustc.edu.cn/debian几分钟就能 Base system installed successfully.。
第二次尝试:从 chroot 到"像个 OS"
裸 chroot 能跑命令,但不算一个系统:没有 systemd、没有服务管理。手动用法是 bind-mount 三个伪文件系统再进去:
R=/media/user/DATA1/debian-arm64
mount --bind /proc $R/proc; mount --bind /sys $R/sys; mount --bind /dev $R/dev
chroot $R /bin/bash在里面装好基础件:
apt install systemd-sysv dbus openssh-server locales sudo vim curl wget顺手把 sshd 配成 2222 端口(宿主机 22 被 Kylin 占着),把宿主机 root 的 authorized_keys 拷进容器 root,免 key 不能登录。
第三次尝试:systemd-nspawn
systemd-nspawn 是 systemd 自带的容器工具,可以理解为"systemd 原生的 chroot++":它给容器套齐 6 个命名空间(mount/pid/net/ipc/uts/cgroup),用 pivot_root 换根,cgroup 框资源,容器里的 systemd 作为 PID 1 完整启动。没有守护进程,容器就是宿主机上一棵普通的进程树,宿主机 systemctl 直接管。
Kylin 仓库里就有:
apt install systemd-container # 提供 systemd-nspawn启动:
systemd-nspawn -bD /media/user/DATA1/debian-arm64 --machine=trixie-b = boot,找容器里的 systemd 当 init。然后 machinectl list 就能看到一台注册在案的"机器"。
坑 5:stock unit 的 -U 会"偷改"文件属主
systemd 自带的 systemd-nspawn@.service 模板启动参数里有 -U(--private-users=pick),它会给容器做 UID 偏移映射 —— 副作用是递归 chown 整个 rootfs,所有文件属主变成 1277427712 这种天文数字 UID。之后再以非映射模式启动,容器里的 sshd 发现 /root/.ssh/authorized_keys 不属于 root,StrictModes 直接拒登(Permission denied (publickey)),排查半天。
教训:要么一直用 -U,要么一直不用。混用之后修复:
chown -R root:root /media/user/DATA1/debian-arm64我的选择是去掉 -U(自定义 override,见下),代价是容器 root 等于宿主机 root —— 自己用的开发环境,接受。
第四步:独立 IP(macvlan)
stock unit 默认 --network-veth:容器是私有网段,外面访问不到。我想要的是容器作为局域网里一台独立设备,直接从路由器拿 IP。
两种做法:
- 桥接:把宿主机唯一的网卡(RTL8153 USB)桥进 br0。完美互通,但我是 SSH 远程操作,改唯一网卡配置,配错就失联,需要人去现场捅显示器。
- macvlan:不动宿主机网络分毫,在物理网卡上虚拟一块"分身网卡"塞进容器。零失联风险,代价是宿主机自己访问不到容器的 IP(macvlan 特性,数据不过宿主协议栈),局域网其他机器都正常。
远程操作,选 macvlan 没有悬念。写个 override:
# /etc/systemd/system/systemd-nspawn@trixie.service.d/override.conf
[Unit]
Requires=media-user-DATA1.mount
After=media-user-DATA1.mount
[Service]
# kysec 执行控制必须关,且要在容器启动前
ExecStartPre=/usr/sbin/setstatus -f exectl -p off
# 防手贱残留的 chroot bind-mount
ExecStartPre=-/bin/umount /media/user/DATA1/debian-arm64/dev/pts
ExecStartPre=-/bin/umount /media/user/DATA1/debian-arm64/dev
ExecStartPre=-/bin/umount /media/user/DATA1/debian-arm64/proc
ExecStartPre=-/bin/umount /media/user/DATA1/debian-arm64/sys
# 替换 stock 的启动行:去掉 -U 和 --network-veth,改 macvlan
ExecStart=
ExecStart=/usr/bin/systemd-nspawn --quiet --keep-unit --boot \
--link-journal=try-guest --network-macvlan=enxa86e4e8ea633 \
--settings=override --machine=%i容器内部配网络(让容器里的 networkd 去 DHCP):
# 容器内 /etc/systemd/network/50-macvlan.network
[Match]
Name=mv-*
[Network]
DHCP=ipv4systemctl enable systemd-networkd # 容器内执行systemctl daemon-reload && systemctl restart systemd-nspawn@trixie,半分钟后:
mv-enxa86e4DKFn UP 10.0.0.127/24 ...
default via 10.0.0.1 dev mv-enxa86e4DKFn proto dhcp路由器眼里,局域网多了一台新设备,分到了 10.0.0.127。RTL8153 这种 USB 网卡跑 macvlan 也毫无压力。
第五步:开机自启的收尾
两个遗留问题:
-
数据盘挂载:之前是桌面 udisks 在用户登录后才挂
/media/user/DATA1,开机时容器会找不到 rootfs。加 fstab 让 systemd 自己挂(nofail防止盘不在时卡死启动):UUID=c3201fc8-... /media/user/DATA1 ext4 defaults,nofail 0 2fstab 接管的盘 udisks 会自动让位,桌面不受影响。
Requires=/After=那两行(上面 override 里)保证容器在盘挂好之后才启动。 -
机器目录:
systemd-nspawn@trixie按约定从/var/lib/machines/trixie找 rootfs,做个软链:mkdir -p /var/lib/machines ln -s /media/user/DATA1/debian-arm64 /var/lib/machines/trixie systemctl enable systemd-nspawn@trixie
齐活。重启宿主机,容器自动起来,ssh 直通。
最终形态
| 宿主机 | Debian 容器 | |
|---|---|---|
| 系统 | Kylin V10 SP1 | Debian 13 (trixie) |
| 内核 | 厂商 5.10.97(共享) | 同左 |
| IP | 10.0.0.247 | 10.0.0.127 |
| 进入方式 | ssh root@10.0.0.247 |
ssh root@10.0.0.127 / machinectl shell trixie |
| 服务管理 | — | 容器内 systemctl 全功能 |
| 开机 | 物理机 | systemd-nspawn@trixie.service 自启 |
资源限制也顺手(在宿主机上对 unit 下刀):
systemctl set-property systemd-nspawn@trixie.service MemoryMax=4G CPUQuota=800%总结
- 信创机不换内核用现代发行版,debootstrap + systemd-nspawn + macvlan 是目前最干净的组合:原生性能、完整 systemd、独立 IP、和宿主机互不干扰。
- 全程不动 bootloader、不动分区、不动原系统,随时
rm -rf归零。 - 坑集中在三处:kysec 执行控制、老 debootstrap 不认识 merged-usr、nspawn
-U的 UID 偏移 chown。记住这三个,能省一晚上。
附:本文环境
- 硬件: 华为擎云 W515X,麒麟 9000C(4×A510 + 6×Taishan + 2×小核),8GB,UFS 256G + 1TB HDD
- 宿主: Kylin V10 SP1,5.10.97-23-9000c,UEFI+DT 启动
- 容器: Debian 13 trixie arm64 minbase + systemd-sysv + openssh-server,systemd-nspawn 245 管理