Why
I just bought a Asus router that sometimes it is overheat like 80C. For cooling, I bought a pair of USB powered fan and it works well, however, it’s waste of energy while CPU is idle. So I think it’s a good idea to use USB control a relay that switch on fan while CPU is hot and turn it off while it’s idle.
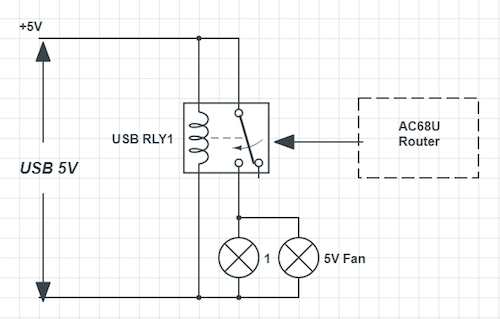
Here is the circle diagram, pretty simple.
bad USB driver
I bought a usb hid relay from Taobao( Chinese version of Ebay) for only $2.5

Putting them together.

But when I try to coding, the vendor didn’t has any kind of opensource code nor protocol to drive this relay 🙁

After painstacking search on Google, I found a project named USB Relay HID, which is same device and implment by … well … C
I love Golang, so why not try it in Golang?
Lucky Serge Zaitsev has already written a pure USB HID driver, which only support Linux and it’s fine to me.
First, I use my Mac to do the cross compile the example code from the usb hid driver project, and scp to my router and it works!
env GOARM=5 GOARCH=arm GOOS=linux go build example/main.go
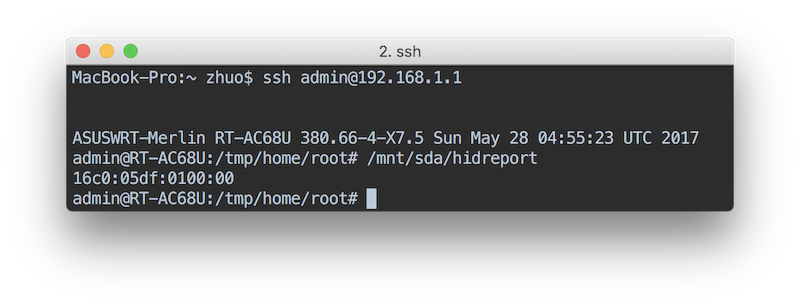
Some note, although RT-AC68U is based on ARMv7 but it don’t have FPU, so don’t try to use GOARM=7 or you will get this error:
Illegal instruction
Now we had done with compiling, let’s take a look at the driver code. Fortunately the code is simple and easy to understand, here is the core control code
if ( relaynum < 0 && (-relaynum) <= 8 ) {
mask = 0xFF;
cmd2 = 0;
if (is_on) {
cmd1 = 0xFE;
maskval = (unsigned char)( (1U << (-relaynum)) - 1 );
} else {
cmd1 = 0xFC;
maskval = 0;
}
} else {
if ( relaynum <= 0 || relaynum > 8 ) {
printerr("Relay number must be 1-8\n");
return 1;
}
mask = (unsigned char)(1U << (relaynum-1));
cmd2 = (unsigned char)relaynum;
if (is_on) {
cmd1 = 0xFF;
maskval = mask;
} else {
cmd1 = 0xFD;
maskval = 0;
}
}
After I copied the code, it just not working, what could possibly gone wrong?
I found some definition of USB requests at USB in nutshell Chapter 6 , for server engineer like me, I think this is a good analogy below.
Node in the networking -> Device
Application -> Interface
protocol port -> Endpoint
I tried to capture the USB package by Wireshark to see the diffrenece between USB HID RELAY and I own driver.
tcpdump -i usbmon -w cap.pcap
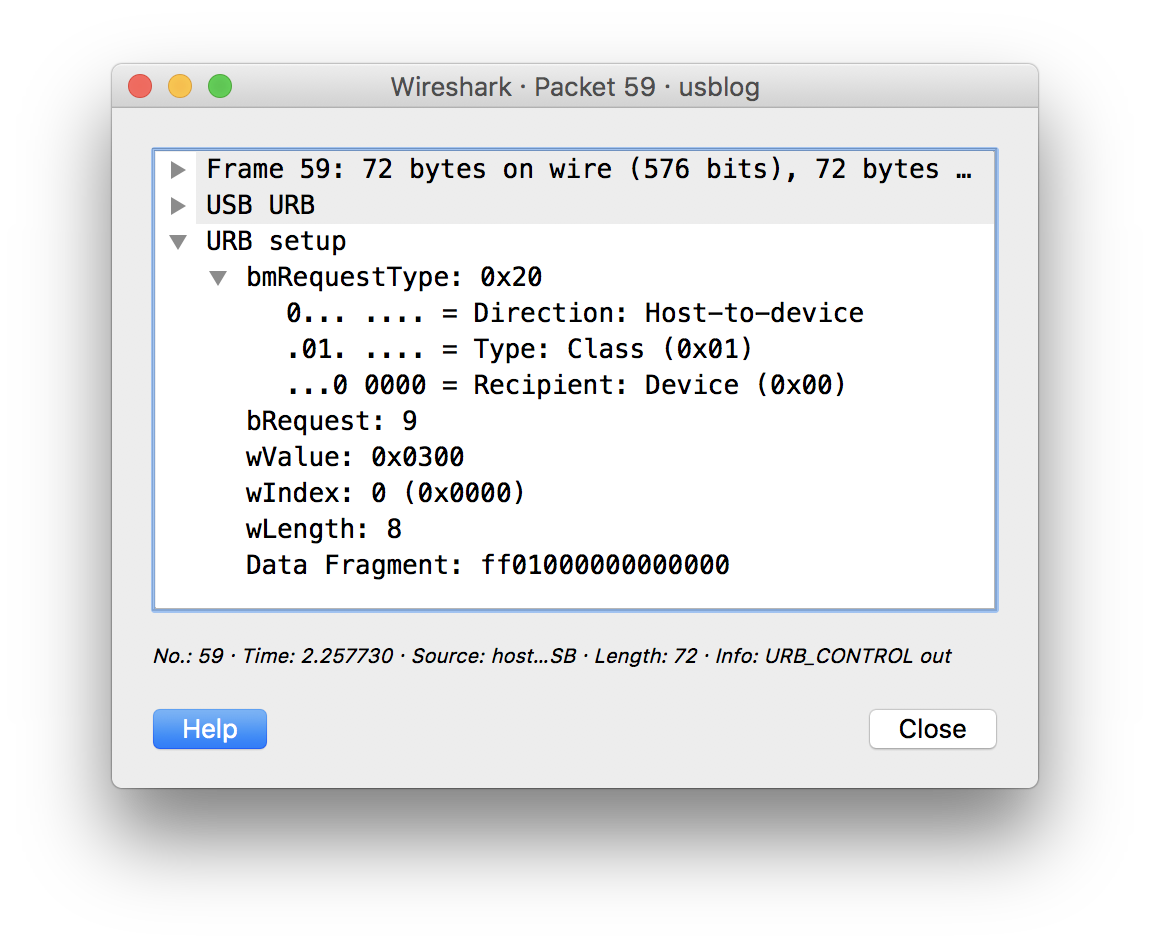
Turns out there is one byte less in the good control request. You can see that at the Data Fragment.
One more thing. Status from relay, I tried to send GetReport request, nothing came back.
I used tcpdump and Wireshark, again.
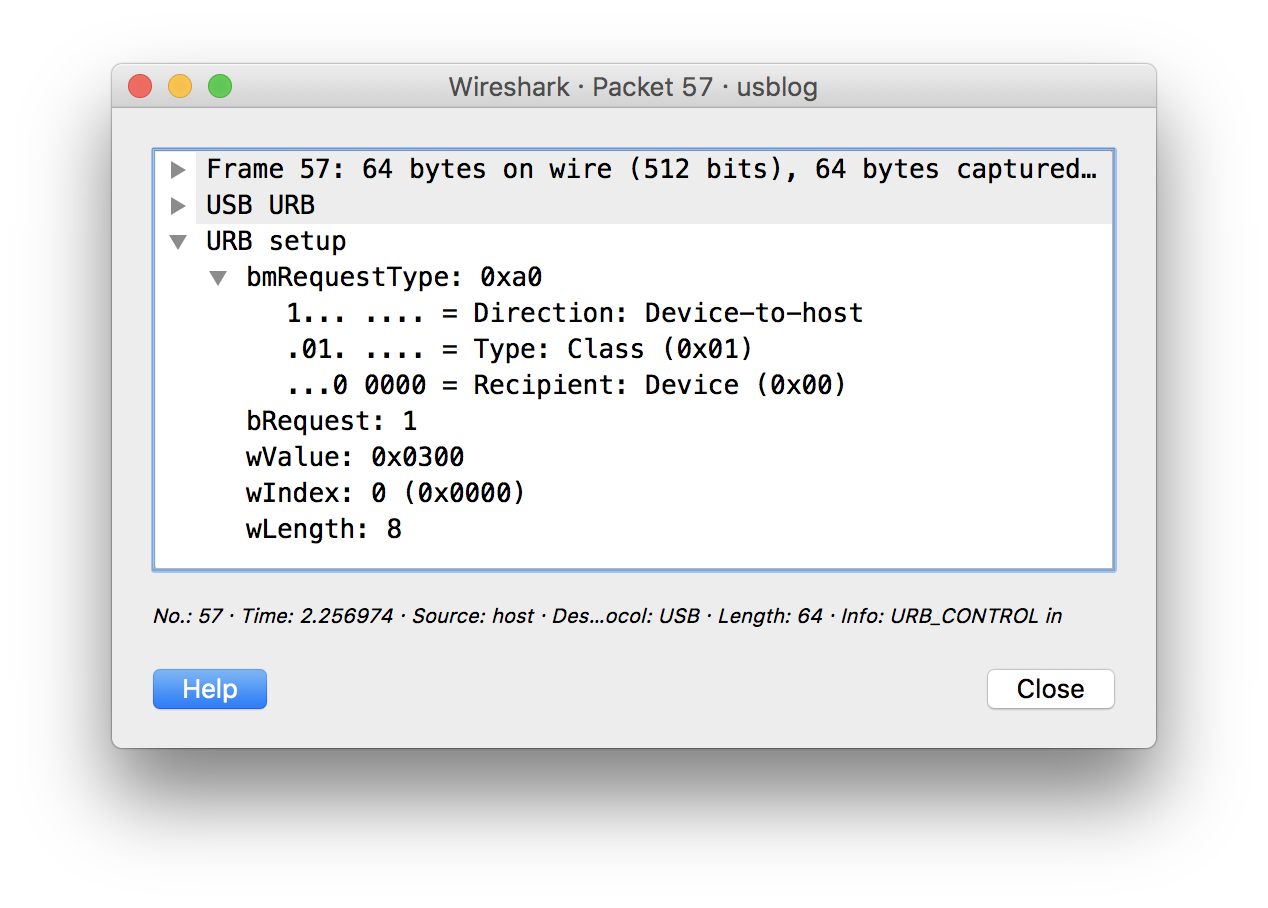
Well, this USB relay vendor using a non stadrad request for the reporting feature. So I have to construct a non standrad request too.
var dev *Relay
dev.Ctrl(0xa0, 0x01, 3<<8, 0x0, buf, 1000)
Compile, execute it, and it works!