上游Google团队的 Keith Randell 6月时抛出一个有趣的话题,由于近年的CPU预测技术的发展,如果Go runtime去掉Duff device,性能反而会达到一定的提升。
原帖:https://groups.google.com/g/golang-dev/c/bVoLyx0s3tg
我摘出来有趣的部分并翻译了下:
达夫设备(Duff's Device) 通过在运行时部署一个大规模展开的清零/复制循环来优化内存清零和内存复制操作。编译器会合成一个跳转指令,直接跳转到这个展开循环的特定中间位置,以精确执行所需次数的循环操作。
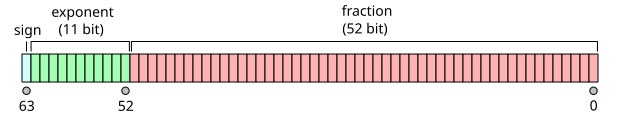
在Go语言中,其实现形式类似于:s[0] = 0; s = s[1:] s[0] = 0; s = s[1:] s[0] = 0; s = s[1:] ...大量重复指令... s[0] = 0; s = s[1:] s[0] = 0; s = s[1:] s[0] = 0; s = s[1:] return当编译器需要清零7个字节时,它会计算从末尾倒数第7条指令的地址并直接跳转执行。
这听起来很巧妙,但每次调用都会产生额外开销。况且现代分支预测器已非常高效,消除调用点的循环开销并不再那么重要。
Keith 还提供了几个CL,不过ARM64/AMD64 的实现是不管对齐的问题的,这就意味着 RISC-V 不能这样用(因为 RISC-V 的 unalignement access 是臭名昭著的软件实现/内核 trap/性能损失大)我决定自己实现 type alignment 的版本。
Keith 版 SSA 非常简洁
(Zero [s] ptr mem) && s > 16 && s < 192 => (LoweredZero [s] ptr mem)
(Zero [s] ptr mem) && s >= 192 => (LoweredZeroLoop [s] ptr mem)然后编写对应的 code gen 就可以了,但……RISCV就麻烦了,因为要传入一个type alignment进去
(Zero [s] {t} ptr mem) =>
(LoweredZero [t.Alignment()]
ptr
(ADD <ptr.Type> ptr (MOVDconst [s-moveSize(t.Alignment(), config)]))
mem)如果直接塞多一个参数,变成
(Zero [s] {t} ptr mem) =>
(LoweredZero [s]
ptr
(MOVconst [t.Alignment()])
mem)这样在materialize的时候就会多一个MOV const, reg的指令,这样不优雅!
然后想到bit shift,把LoweredZero [s<<32|t.Alignment()],但这样在SSA优化的时候,mem size就非常恐怖了……怎么样优雅的把这个值塞进 AuxInt,就成了头大的问题。
只好看看 SSA compiler 的实现,然后在 AuxInt 的 type list (cmd/compile/internal/ssa/op.go)发现了“auxARM64BitField”
// architecture specific aux types
auxARM64BitField // aux is an arm64 bitfield lsb and width packed into auxInt给 RISC-V 直接套上,就会造成程序的文不对题。
改成auxRISCVBitFields,还要加几个前置CL来实现。这不优雅!
于是我全部类型都看了遍,终于发现一个合理的:"SymValAndOff",代价就是……Lowered(Zero|Move)需要添加一个 symEffect 说明这个指令有啥副作用(当然都是Write啦),这下就优雅多了
(Zero [s] {t} ptr mem) && s <= 24*moveSize(t.Alignment(), config) =>
(LoweredZero [makeValAndOff(int32(s),int32(t.Alignment()))] ptr mem)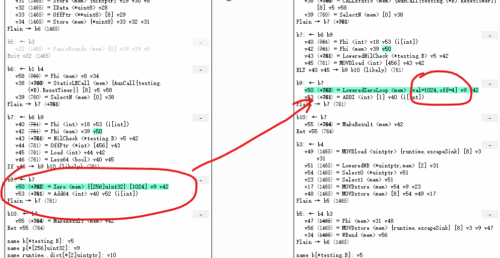
完美!
然后测试性能发现,咦,Zero竟然没有任何改进?
MemclrKnownSize112-4 5.602Gi ± 0% 5.601Gi ± 0% ~ (p=0.363 n=10)
MemclrKnownSize128-4 6.933Gi ± 1% 6.545Gi ± 1% -5.59% (p=0.000 n=10)
MemclrKnownSize192-4 8.055Gi ± 1% 7.804Gi ± 0% -3.12% (p=0.000 n=10)
MemclrKnownSize248-4 8.489Gi ± 0% 8.718Gi ± 0% +2.69% (p=0.000 n=10)
MemclrKnownSize256-4 8.762Gi ± 0% 8.763Gi ± 0% ~ (p=0.494 n=10)
MemclrKnownSize512-4 9.514Gi ± 1% 9.514Gi ± 0% ~ (p=0.529 n=10)
MemclrKnownSize1024-4 9.940Gi ± 0% 9.939Gi ± 1% ~ (p=0.989 n=10)再次祭出SSA debuger,发现,原来runtime的memclr都跑去调用memNoPtrClr了……那自然不会用咱们这个LoweredZeroOp。
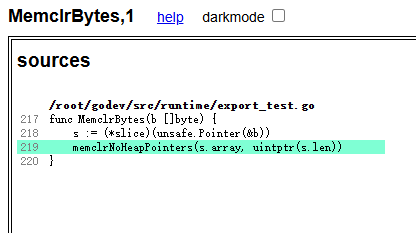
然后改用了基于SSA Zero的ClearFat,才有下面的测试结果(删掉了部分不重要的)
ClearFat3-4 1.300Gi ± 0% 1.301Gi ± 0% ~ (p=0.447 n=10)
ClearFat4-4 3.902Gi ± 0% 3.902Gi ± 0% ~ (p=0.971 n=10)
……
ClearFat16-4 1.600Gi ± 0% 5.202Gi ± 0% +225.10% (p=0.000 n=10)
ClearFat18-4 1.018Gi ± 0% 1.300Gi ± 0% +27.77% (p=0.000 n=10)
ClearFat20-4 2.601Gi ± 0% 4.938Gi ± 12% +89.87% (p=0.000 n=10)
ClearFat24-4 2.601Gi ± 0% 5.201Gi ± 0% +99.96% (p=0.000 n=10)
ClearFat32-4 1.982Gi ± 0% 5.203Gi ± 0% +162.55% (p=0.000 n=10)
ClearFat56-4 3.640Gi ± 0% 5.201Gi ± 0% +42.88% (p=0.000 n=10)
ClearFat64-4 2.250Gi ± 0% 5.202Gi ± 0% +131.25% (p=0.000 n=10)
……
geomean 2.005Gi 3.020Gi +50.58%可以看到原来的小byte的实现不变(没改,当然没变),到了16 bytes 就突然涨起来,我看了下原版的是有优化的,理论上应该不变啊
(Zero [16] {t} ptr mem) && t.Alignment()%8 == 0 =>
(MOVDstore [8] ptr (MOVDconst [0])
(MOVDstore ptr (MOVDconst [0]) mem))原来ClearFat的type alignment是 uint32 (也就是4 bytes),所以没有优化,就落到了循环实现(连TM duff也要求 8 bytes alignment)
func BenchmarkClearFat16(b *testing.B) {
p := new([16 / 4]uint32)
Escape(p)
b.ResetTimer()
for i := 0; i < b.N; i++ {
*p = [16 / 4]uint32{}
}
} 既然如此,那我就白捡个性能优化225%吧 :)