背景
Go怎么获取当前时间?问一个会Go的程序员,他随手就能写这个出来给你。
import time
time.Now()
这背后是一个系统调用,X86上调用SYSCALL来完成,ARM64上是SVC。
// func walltime() (sec int64, nsec int32)
TEXT runtime·walltime(SB),NOSPLIT,$24-12
MOVW $0, R0 // CLOCK_REALTIME
MOVD RSP, R1
MOVD $SYS_clock_gettime, R8
SVC
MOVD 0(RSP), R3 // sec
MOVD 8(RSP), R5 // nsec
MOVD R3, sec+0(FP)
MOVW R5, nsec+8(FP)
RET
- R0 分别是调用的时钟类型
- R1 是对应的Stack Pointer
- R8 系统调用的ID
很简单吧?但是这里有一个优化点,就是SVC涉及到了内核态和用户态的切换,
其实就是把所有的用户态的寄存器存储在内核的栈上,执行完内核函数之后,再恢复回来。
这一来一回,速度就降下来了……
而时间又是很常见的系统调用,且是只读数据,能不能不切换内核/用户态呢?
Linux内核的开发者们提出了vDSO方案。
通过给每个用户态进程添加一个共享对象(virtual dynamic shared object)来提供一些常见的内核函数
这样就不用切换用户态了。
寻找vDSO
Go对于linux_amd64 vDSO已经优化得很到位了
包括ELF库的解析和使用。比较关键的代码是下面这段。
runtime/vdso_linux_amd64.go
var sym_keys = []symbol_key{
// ...
{"__vdso_clock_gettime", 0xd35ec75, 0x6e43a318, &__vdso_clock_gettime_sym},
}
// initialize with vsyscall fallbacks
var (
// ...
__vdso_clock_gettime_sym uintptr = 0
)
ARM64位也填上一样的值就可以了吧?
然而,现实是,照抄的不行,跟x86的名字和版本都不一样(摔!
man 7 vdso
aarch64 functions
The table below lists the symbols exported by the vDSO.
symbol version
──────────────────────────────────────
__kernel_rt_sigreturn LINUX_2.6.39
__kernel_gettimeofday LINUX_2.6.39
__kernel_clock_gettime LINUX_2.6.39
__kernel_clock_getres LINUX_2.6.39
好好好,我调整一下代码
注意这个后面的0x75fcb89,vDSO代码需要校验,我通过gdb跟踪才最终查到的。
vdso_linux_arm64.go
var vdsoLinuxVersion = vdsoVersionKey{"LINUX_2.6.39", 0x75fcb89}
var vdsoSymbolKeys = []vdsoSymbolKey{
{"__kernel_clock_gettime", 0xd35ec75, 0x6e43a318, &vdsoClockgettimeSym},
}
// initialize to fall back to syscall
var vdsoClockgettimeSym uintptr = 0
发起vDSO call
其实vDSO跟系统调用使用了同样的参数,都是R0 类型,R1 SP, 理论上直接BL 到vDSO函数地址即可。
但不一致的地方是,vDSO需要更大的栈空间。
因此需要切换SP地址到M的第一个g上,即g0,调度器g0栈32K,一般只有2K,如果不是,就查找g0的SP地址并切换,在函数结束时切换回当前的g。
MOVD m_curg(R21), R0 // m_curg 其实是个宏,展开后是取当前m的g0
CMP g, R0
BNE noswitch
MOVD m_g0(R21), R3 // m_g0 也是个宏,展开后就是读取m的g0地址
MOVD (g_sched+gobuf_sp)(R3), R1 // Set RSP to g0 stack
noswitch:
SUB $16, R1
BIC $15, R1 // Align for C code
MOVD R1, RSP
pprof的需求
在完成这部分代码后,我发现Ian加了一个追踪vdso调用的pprof
都是照猫画虎,所以就不提了。
最后的提交
runtime: use vDSO for clock_gettime on linux/arm64
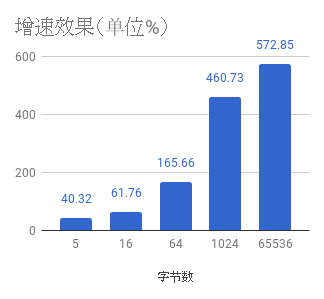
效果能快个66%
name old time/op new time/op delta
TimeNow 442ns ± 0% 163ns ± 0% -63.16% (p=0.000 n=10+10)
不过……内核得支持才行,如果内核没办法使用特定时钟源,还是会进行系统调用。
比如我这块破NanoPC,就不支持
cat /sys/devices/system/clocksource/clocksource0/current_clocksource
source timer
哎……啥时候可以买块Hikey960或者ThunderX2 🙁
2018-04-01 Updates
为什么ARM64下有些内核vDSO比原来还慢呢?
买了块Hikey960试了试,发现还是不能加速vDSO……奇怪了……
我试着在内核里找了找原因。
发现,可能是CPU的bug。
以Linux 4.15 Hikey960为例子。
在/arch/arm64/kernel/vdso/gettimeofday.S
有个宏,每次调用vDSO的vsyscall时,都会检查,而有问题的芯片总是跳到fail上。
.macro syscall_check fail
ldr w_tmp, [vdso_data, #VDSO_USE_SYSCALL]
cbnz w_tmp, \fail
.endm
这个vdso_data就是指针,#VDSO_USE_SYSCALL对应的是use_syscall
use_syscall在/arch/arm64/kernel/vdso.c)初始化时,会调用时钟驱动里的vdso_direct值。
void update_vsyscall(struct timekeeper *tk)
{
u32 use_syscall = !tk->tkr_mono.clock->archdata.vdso_direct;
而我们的Hikey960用的是arch_sys_counter
~ # cat /sys/devices/system/clocksource/clocksource0/current_clocksource
arch_sys_counter
搜了一下,发现在/drivers/clocksource/arm_arch_timer.c
static struct clocksource clocksource_counter = {
.name = "arch_sys_counter",
.rating = 400,
.read = arch_counter_read,
.mask = CLOCKSOURCE_MASK(56),
.flags = CLOCK_SOURCE_IS_CONTINUOUS,
};
精彩的部分来了!
默认情况下,vdso_default是true的,也就是不用vdso
这个时钟源驱动怎么初始化这个vdso_direct改成false的呢?
if (wa->read_cntvct_el0) {
clocksource_counter.archdata.vdso_direct = false;
vdso_default = false;
}
继续追下去,发现是
#ifdef CONFIG_HISILICON_ERRATUM_161010101
/*
* Verify whether the value of the second read is larger than the first by
* less than 32 is the only way to confirm the value is correct, so clear the
* lower 5 bits to check whether the difference is greater than 32 or not.
* Theoretically the erratum should not occur more than twice in succession
* when reading the system counter, but it is possible that some interrupts
* may lead to more than twice read errors, triggering the warning, so setting
* the number of retries far beyond the number of iterations the loop has been
* observed to take.
*/
#define __hisi_161010101_read_reg(reg) ({ \
u64 _old, _new; \
int _retries = 50; \
\
do { \
_old = read_sysreg(reg); \
_new = read_sysreg(reg); \
_retries--; \
} while (unlikely((_new - _old) >> 5) && _retries); \
\
WARN_ON_ONCE(!_retries); \
_new; \
})
按理说,这个_new值应该就是>1的,实际上就是bool 的true。这样,vdso_direct就应该是false,即启用vdso了。
但是……我们的CPU 没有通过这个,应该就是CPU的bug了 🙁