Goost库终于发布了,最开始只有base64和adler32(其实就是捡Go官方废弃的汇编加速代码来)
这次我添加了base64 arm64加速的优化,性能提升不高,也就2x,arm处理器羸弱的流水线这锅是跑不了了。
代码如下:
本文记录一下这两天的思路和总结
base64编码基础
base64很简单,数据按6bit(2^6=64)分隔并转换成可见ASCII编码内的字符就可以了,不是我们常见的8bit分隔。具体可以看Wikipedia,这里就不赘述了。
如何加速?
其实早就人研究好了Base64 encoding with SIMD instructions,只不过没有arm64版本的文章。
这里就大致翻译下上面文章的思路,一些解释和背景讲解:
- 中括号[] 代表一个字节
- aaaaaa代表一个base64字符
在内存里,3个字节数据是这样排布的。
[aaaaaabb][bbbbcccc][ccdddddd]
而我们的目标是:
[__aaaaaa][__bbbbbb][__cccccc][__dddddd]
接下来大致分三步:首先借助的是arm64 的ld3指令将上面的3个连续字符载入至三个不同的向量寄存器v0, v1, v2
v0: [aaaaaabb]....
v1: [bbbbcccc]....
v2: [ccdddddd]....
通过VSHL,VSHR指令,转到四个对应的向量寄存器,以bbbbbb为例:
aaaaaabb << 4 = aabb____
bbbbcccc >> 4 = ____bbbb
接下来用or,mask将bbbbbb保留
最后这步最好玩。arm64支持VTBL(向量查表操作),恰好最多支持4个128bit的表查询(正好64个字节),所以只需要把base64的码表塞进查询向量寄存器中即可
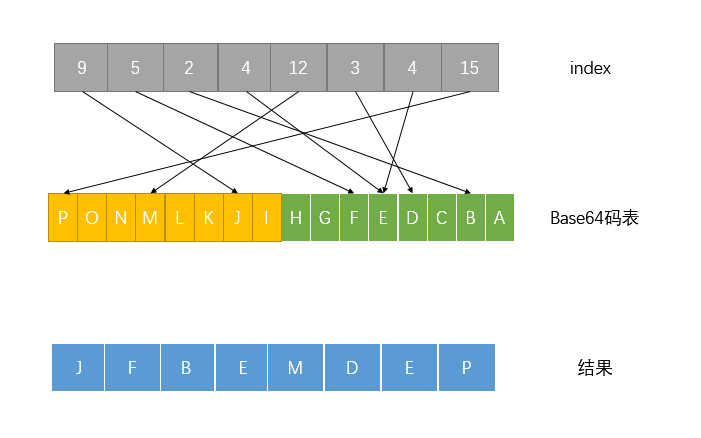
最后st4保存四个向量寄存器到目的地址即可。
总结一下
写的时候还是碰到了一个坑,因为对VSRI和VSHR区别不熟悉,加上Go编译器只支持VSRI(vector shift right and insert),这个insert会保留原有向量寄存器的数据,导致总是在3/27/53这三个位置的数据不对。浪费了不少时间,下次有不熟悉的指令还是多读读手册。不过误打误撞倒是比原来的作者少了2个指令哈哈。
看原文的时候总是沉不下心,看不懂,下次还是要带着问题读。
解码感觉有些复杂,而且原文的实现不太方便,回头再研究一下。