因为最近树莓派的nVME因为突然断电数据损坏了,所以捡个垃圾的块带电池的RAID 卡,给自己的esxi机器整上,毕竟现在重要数据都在上面了……总不能真的All in one,断电后就全部嗝屁了吧。买了2块1TSSD,组个SAS 8087 RAID1。配置如下:
- CPU:10 CPUs x Intel(R) Xeon(R) W-2150B CPU @ 3.00GHz
- 主板:Supermicro X11SRM-F 单路
- RAID卡:Adaptec 6805T 512MB Cache 6G SAS
- ESXI:ESXI6.7

开机后按Ctrl+A,开启RAID BIOS
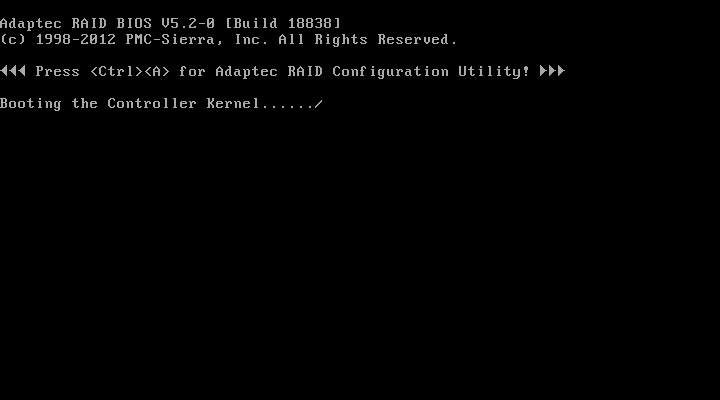
选择Create Array,设定对应的RAID类型,我这里选了RAID1
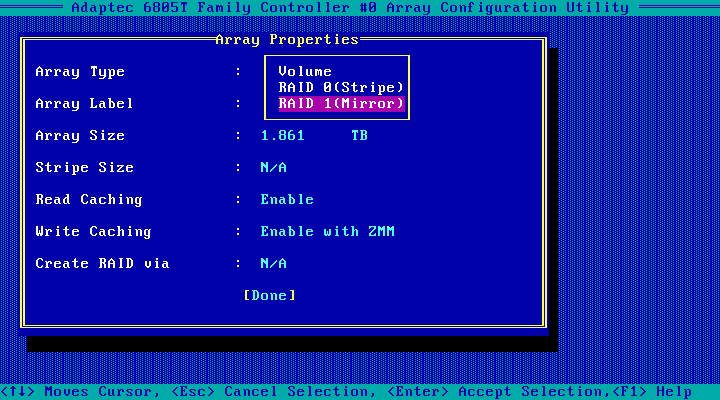
注意这里一定要启用两个Cache,要不然速度只有20M/s。保存并重启后,你会发现ESXI6.7 还识别不出来,这是因为没有驱动,得自己装……一顿搜索才找到,为了以后哪个倒霉蛋不要跟我一样找半天,我先扔这里了aacraid-6.0.6.2.1.57013-11 959565.zip。这下终于出来了。
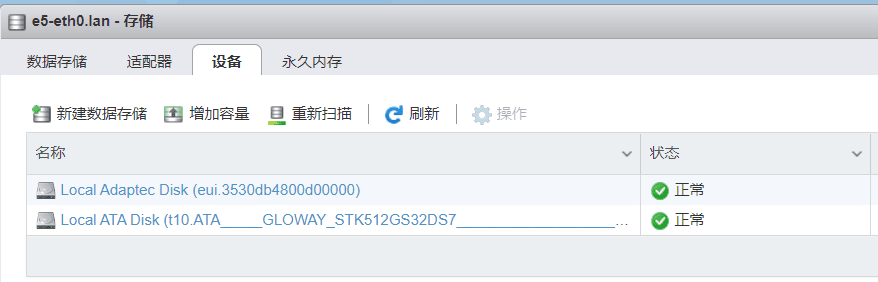
倒是装上RAID之后,我发现磁盘性变得很奇怪……
小文件读写特别差,但是大文件又爆炸的好,我测试的是(1G文件读写,RAID才512M缓存),vmfs 6的磁盘格式(块1M),调整了RAID的读写模型成OLTP/DB 反而更差,希望有人能指出为啥
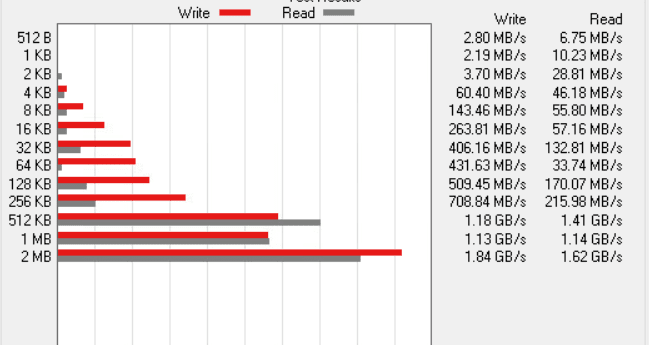
受不了老RAID的性能了,全部换成LSI2308 的raid卡了,但是性能惨不忍睹,BIOS自带的设置里并没有WriteCache,一顿搜索后发现了这个宝藏文章和lsiutil这个工具,可以拿来开启LSI RAID的写缓存!不过这个预先要求有mpt2sas这个驱动。
先安装mpt2sas,允许安装社区的驱动,使用下面的ssh命令,注意:必须用全路径(esxi装软件奇怪的要求)
esxcli software vib install -v <到驱动的全路径>/scsi-mpt2sas-20.00.01.00-1OEM.550.0.0.1331820.x86_64.vib
Installation Result
Message: The update completed successfully, but the system needs to be rebooted for the changes to be effective.
Reboot Required: true
VIBs Installed: Avago_bootbank_scsi-mpt2sas_20.00.01.00-1OEM.550.0.0.1331820
VIBs Removed: VMW_bootbank_scsi-mpt2sas_19.00.00.00-2vmw.670.0.0.8169922
VIBs Skipped:
安装好,重启后,使用./lsiutil来变更writecache设置
LSI Logic MPT Configuration Utility, Version 1.71, Sep 18, 2013
sh: /sbin/modprobe: not found
mknod: /dev/mptctl: Function not implemented
1 MPT Port found
Port Name Chip Vendor/Type/Rev MPT Rev Firmware Rev IOC
1. ioc0 LSI Logic SAS2308 D1 200 14000700 0
# 输入21,选择RAID 操作
21. RAID actions
# 输入32,选择变更RAID设置
RAID actions menu, select an option: [1-99 or e/p/w or 0 to quit] 32
Volume 0 is DevHandle 011d, Bus 1 Target 1, Type RAID1 (Mirroring)
Volume 1 is DevHandle 011e, Bus 1 Target 0, Type RAID1 (Mirroring)
# 输入0,选择对应RAID盘
Volume: [0-1 or RETURN to quit] 0
Volume 0 Settings: write caching enabled, auto configure hot swap enabled
Volume 0 draws from Hot Spare Pools: 0
Write caching: [0=Disabled, 1=Enabled, 2=MemberControlled, default is 1]
# 输入1,打开Write Cache!