本文将涉及
- 基础电路
- Go交叉编译(cross compile)
- USB原理和驱动
- Wireshark抓USB包
- 一些吐槽
前因
最近发现路由器的温度在负载高时(Time Machine备份时),常常能飙升到80C,于是我从X宝上买了一对5V USB电压驱动的风扇。
发现降温效果不错,能降到55C,但是负载低时,路由器的温度才65C左右,又不需要风扇了。再到X宝上搜索USB可程控的开关或者风扇,发现压根没有,于是萌生了自己做一个Go版本的温控风扇的想法,当然最好是不用拆机,直接用USB供电.
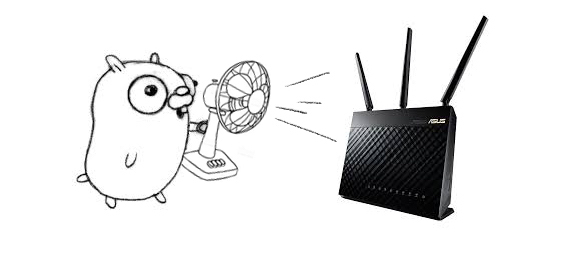
说干就干!原理其实很简单,就是USB控制一个开关。电路图如下:
蛋疼的现实
上X宝,随便买了一个USB 免驱 继电器

电路部分不难~

结果货到的时候发现,对方没有开源技术资料,所谓免驱,只是这个继电器用的是USB HID(就是驱动鼠标键盘)的接口。而真正的控制驱动代码是Windows版的……还是闭源的DLL……
页面上还有一个明显是复制粘贴来的公告……
我们提供应用程序和C++二次开发库代码,没有VB代码,但是都是dll文件,所以能否在VB上操作,需要熟悉VB的朋友自己尝试。由于工程师出深造,没法给您提供技术支持,所以拍前请先看资料
里面是产品所有的资料,已经很详细了,看是否有您需要的东西再考虑购买,给您带来不便请多包涵。

经过一番搜索,发现被坑的不止我一个,国外的哥们都被Ebay上的这个所谓外贸产品(共同点是USB ID 16c0:05df)坑惨了,还专门写了一个项目USB Relay HID,来驱动这些免驱的USB继电器。
这下好了,我看了一下实现,都是通过libusb这个库来控制的,虽然驱动代码有了,但是是C写的,我希望用Go实现,(毕竟C苦手……
又搜索了一圈,各种Go的binding都是用了cgo,这是我一个Go爱好者无法容忍的。
要就要上纯Go!
幸好,来自乌克兰的叫Serge Zaitsev的小哥写了不太完整的纯Go的HID驱动,说只支持x86 Linux,不过没差,大不了我移植一下嘛~
更蛋疼的实现过程
我试着直接用我的Mac交叉编译一次HID驱动里的例子代码
env GOARM=5 GOARCH=arm GOOS=linux go build example/main.go
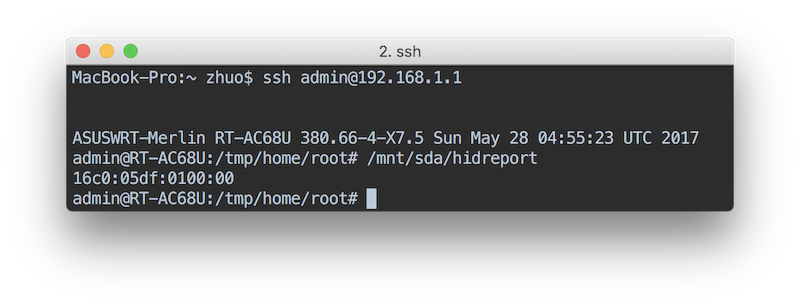
丢在路由器上,能跑!
注意一下,RT-AC68U虽然是ARMv7的,但是丫竟然没有FPU,所以直接使用GOARM=7的话,会报错
Illegal instruction
解决完编译的问题,现在来看看驱动。USB Relay HID项目好在代码量不大。最核心的代码是这段开关控制代码
if ( relaynum < 0 && (-relaynum) <= 8 ) {
mask = 0xFF;
cmd2 = 0;
if (is_on) {
cmd1 = 0xFE;
maskval = (unsigned char)( (1U << (-relaynum)) - 1 );
} else {
cmd1 = 0xFC;
maskval = 0;
}
} else {
if ( relaynum <= 0 || relaynum > 8 ) {
printerr("Relay number must be 1-8\n");
return 1;
}
mask = (unsigned char)(1U << (relaynum-1));
cmd2 = (unsigned char)relaynum;
if (is_on) {
cmd1 = 0xFF;
maskval = mask;
} else {
cmd1 = 0xFD;
maskval = 0;
}
}
啊哈!原来只需要设置一下控制位,并发送set_feature就可以开关继电器,例如打开1号继电器,只需要传递
[]byte{0, 0xff, 0x1}
我迅速地开始抄袭(误 对应的Go代码,并不能工作……
到底哪里出错了,我开始一一核对代码,还是不能理解这USB驱动代码,于是我开始找USB相关资料,看看到底这是个什么玩意。
结果在知乎上一个解释让我豁然开朗,原帖是纯文字,我觉得转化成图例应该更形象,左边是服务端开发常用的术语,右边是USB对应的名词
物理设备 -> Device
应用程序 -> Interface
应用端口 -> Endpoint
在USB in nutshell 第6章中,我查询到了对应的控制数据包定义。
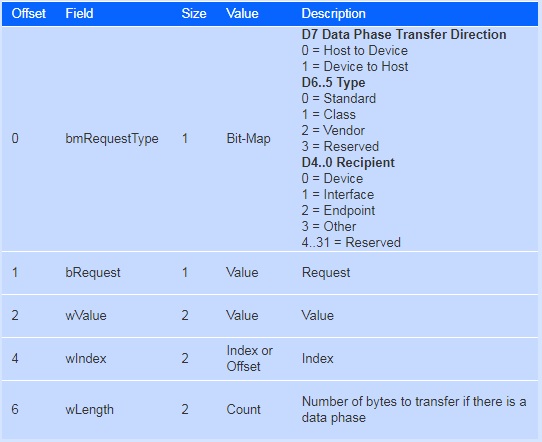
对应起来就是
- bmRequestType指的是请求类型+请求对象+数据方向的一个bit-map,相当于一个UDP/IP包
- bmRequest,相当于调用什么RPC接口
- wValue,wIndex, wLength这些就相当于数据包的内容。
修改好代码后,还是没办法控制,于是我想到了Wireshark抓USB包的方法,来对比我的驱动代码和USB HID RELAY之间的区别。
编译好usb hid relay后
tcpdump -i usbmon -w cap.pcap
对比两个发出的数据,发现原来没有前面的0(满头黑线中= =|||
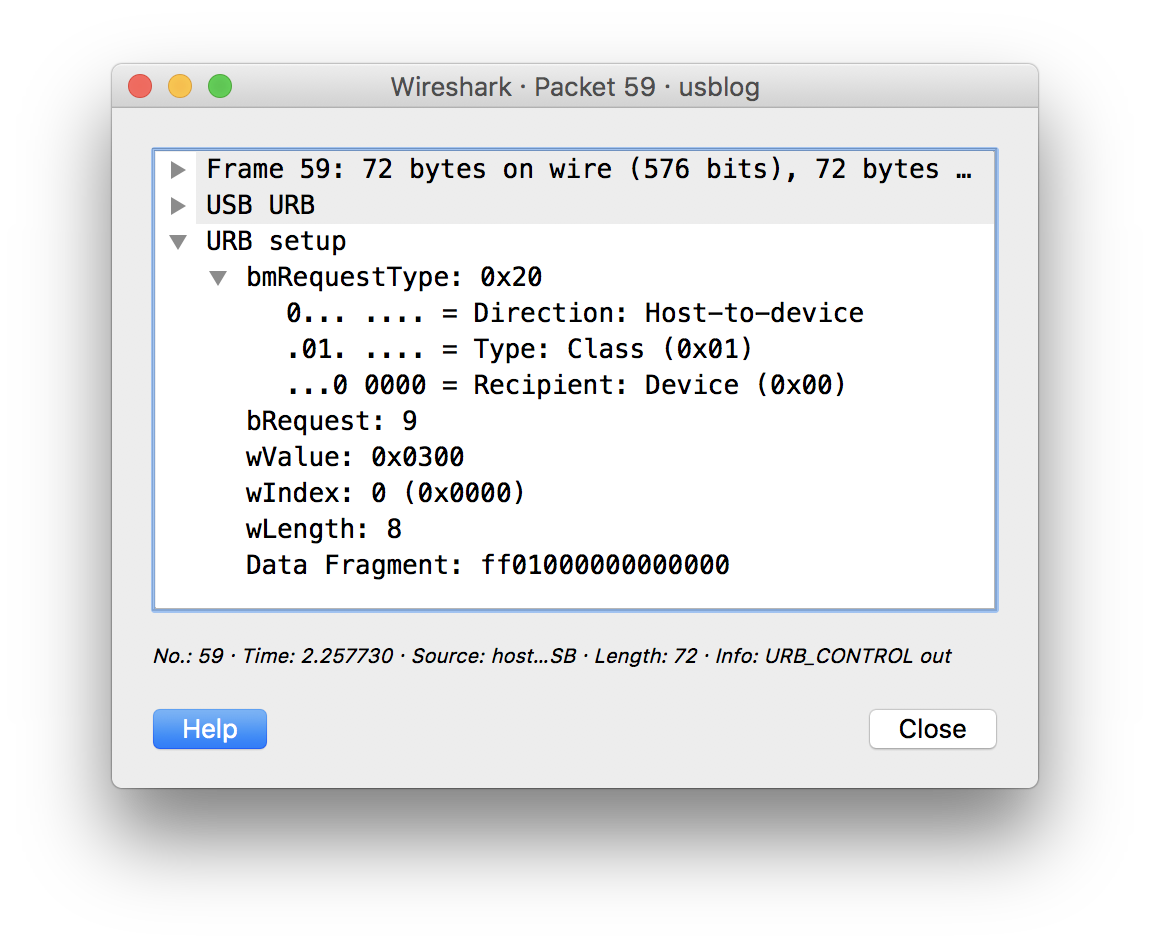
注意看最后一行,有个Data Fragment,是驱动的关键,仿造这个数据包,就驱动开关了。
但是还有一个问题,就是获取开关的状态。我试着发送GetReport指令,但是没有任何返回。再次抓包对比,发现原来这个USB驱动用的不是标准接口……
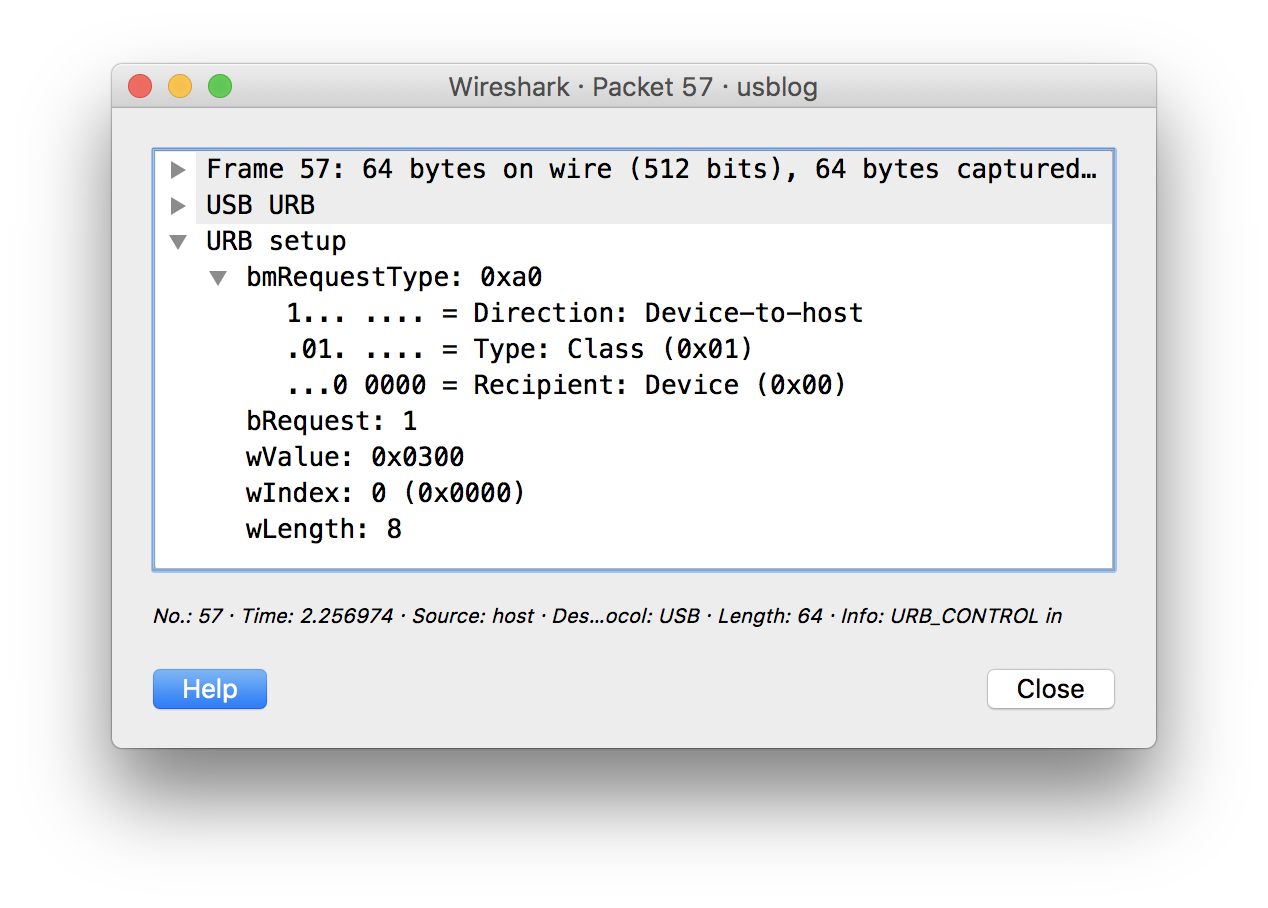
而Go的驱动不支持不标准的请求,也就是我说不完整的原因,碰上不标准的厂商,只能抓瞎。于是我开始改造,发现很简单,只需要把原来私有的方法export出来就可以了。
+func (hid *usbDevice) Ctrl(rtype, req, val, index int, data []byte, t int) (int, error) {
+ return hid.ctrl(rtype, req, val, index, data, t)
+}
这样就可以达到自定义消息的目的了。
var dev *Relay
dev.Ctrl(0xa0, 0x01, 3<<8, 0x0, buf, 1000)
最后测试一下,完美!