本文为部分翻译、整理。 原文为Go的开发者之一的Dave Cheney所做的 Five things that make go
fast
清晰赋值类型
例如,有一个绝对不会超过uint32的数值,就不要用int var gocon uint32 = 2015 这样gocon这个值只会占用4个字节
为啥呢? 因为如下图,CPU的处理速度已经远超内存的总线速度了 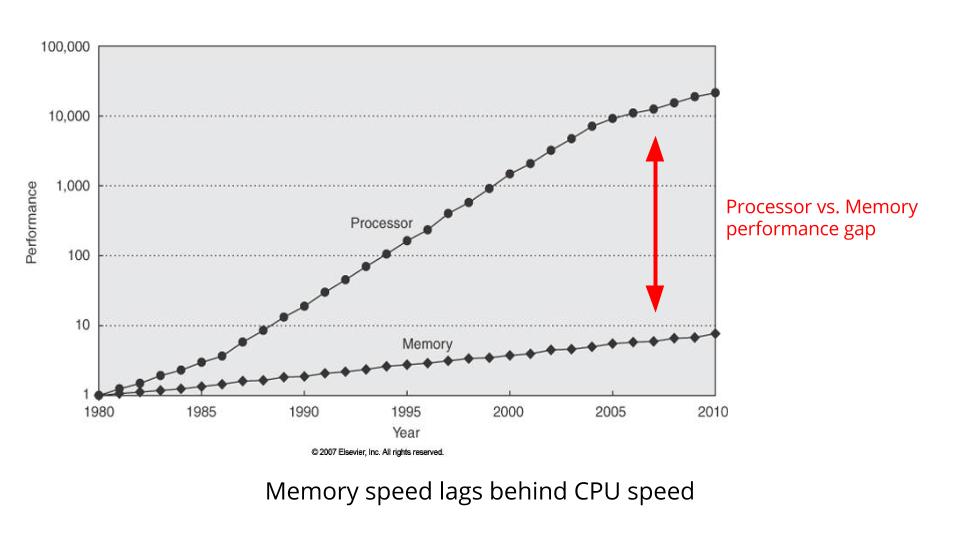 所以数值能用小的用小的,尽量让数值留在CPU
所以数值能用小的用小的,尽量让数值留在CPU
cache,而不是速度更慢的内存里
函数调用有overhead,为了内联,尽量消除编译器无法侦测的dead code
当函数调用时,始终是由overhead(额外开销)的,比如保存调用栈,CPU切出。
因此编译器会尝试进行内联,将小函数直接复制并编译。
举个栗子:
func Max(a,b int) int {
if a > b {
return a
}
return b
}
func DoubleMax(a, b) int {
return 2 * Max(a,b)
}
-m 查看内联状态 $go build -gcflags=-m main.go # utils src/utils/max.go:4: can inline Max src/utils/max.go:11: inlining call to Max
这样做的代价是可执行的二进制文件更大了,但由于内联,并不是函数调用,性能自然是更好了。 但有些函数,是不能内联的,比如下面这个
func Test() bool {return False}
func Expensive() {
if test(){ //接下来的Expensive没办法内联
// Expensive....
}
}
改成下面这样就可以内联了
const TEST = False
func Expensive() {
if TEST{
// Expensive....
}
}
逃逸检查
首先,要理解一个概念,stack 和 heap 
stack作用域是本地的(locals),在函数执行完之后会自动收回,CPU控制,效率高 而heap则需要由程序来管理,效率低 具体有篇文章讲这个:
Memory stack vs
heap
因此,就算有GC,也应该把不需要传出的参数尽量控制在函数内。 例如下图的程序
 因为numbers 只在
因为numbers 只在
Sum中,编译器也会自动分配100个int空间在stack中,而不是heap中。 正因为在stack 中,所以不需要GC参与,自动收回。
但这不意味着不能用指针引用,见第二个栗子: 
尽管变量c是通过new函数生成的,但是因为在center外没有c的引用,所以c也会被存储在stack上。 逃逸检查实例:

Goroutine
第四个,我觉得是提示吧: Goroutine是比进程、线程都小的执行单元 Goroutine中的会被调度器(scheduler)切出的操作:
- chan 收发
- go 语句调用函数
- 阻塞的syscall
- gc
一图胜千言,下图表示了调度器是如何在goroutine之间切换的。 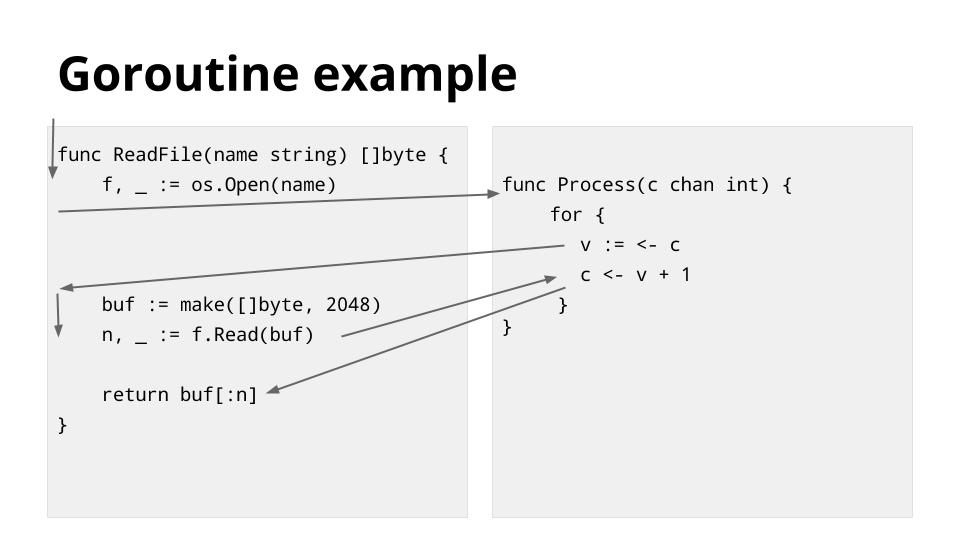
第五个算是对Go1.3以后的stack分配机制的总结,我就不翻译了,有兴趣的同学自己可以看看原文:)
总结
- 我想补充的是: 逃逸对于channel也是成立的,因此,在channel之间,最好传递的也是对象,而不是引用。这个问题上我栽过一次了哈哈哈
- 之前我并不知道内联是啥,Golang、pypy这样的JIT、或者cpython真的是减轻了我的心智负担,当然,了解一下也是很不错的。
- 清晰的赋值个人感觉不是很必要,因为Go的int类型最大是2**31-1,性能调优的时候再认真地梳理其实也来得及