ZeroMQ有一对Pub/Sub socket 类型,但是网上的教程一般侧重于使用TCP版本的……
虽然TCP版本的也能组网,但是略显麻烦,今天我来给大家介绍一下基于PGM协议的ZeroMQ Pub/Sub模型 首先要编译安装OpenPGM brew install libpgm 接着是zmq brew install zmq --with-pgm 这样就准备好了环境了,
这里需要了解一下PGM网络的原理,很简单,如下图 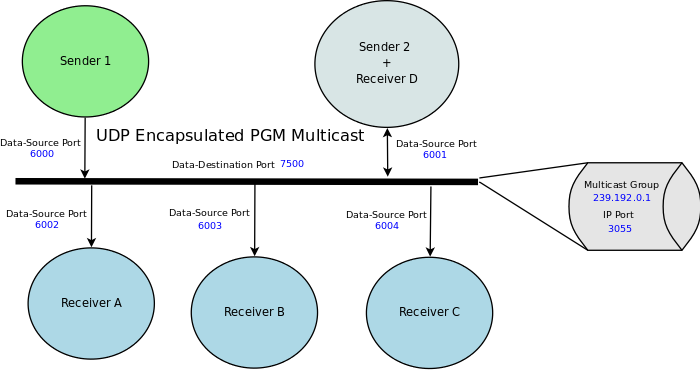
绿色的就是发送方,向目的组播地址239.192.0.1 端口3055(黑色粗线)发送数据,然后所有监听此端口的接收者(Receiver)都收到了。
就这么简单。 然后就是写代码咯:
soc = zmq.NewSocket(zmq.PUB)
soc.Connect("epgm://192.168.1.100;239.192.0.1:3055")
soc.SendMessage("Hi")
呃……192.168.1.100? 这个是pgm的特点,你需要指定发送组播包的网卡名,一般人记不住网卡名……所以用此网卡所持有的IP来标示。 p.s.
- PGM有个特点,就是发送方进行流量控制,zmq中使用的是setrate,切记在Connect之前使用
- zmq会整理包,所以再散的数据,都会组合成一个message发送出来(不愧是智能网络)
- 实际测试时……16Mbps的流量根本不是问题
- 需要debug PGM时
export PGM_MIN_LOG_LEVEL=TRACE
](https://mzh.io/2014/12/go-11-is-released_gopherbiplane5.jpg){kind=link}