本文需要你有写Golang代码经验,阅读大概需要20分钟。
最近一直在研究Go的依赖注入(dependency
injection),方便日后写比较容易测试的代码(以便偷懒)。目前学到ast解析代码,现拿出来跟大家分享一下:)
Tokenizer 和 Lexical anaylizer
如果你知道tokenizer和lexical anaylizer是什么的话,请跳到下一章,不熟的话请看下面这个最简单的go代码
package main
func main() {
println("Hello, World!")
}
这段go代码做了什么?很简单吧,package是main,定义了个main函数,main函数里调用了println函数,参数是"Hello,
World!"。好,你是知道了,可当你运行go
run时,go怎么知道的?go先要把你的代码打散成自己可以理解的构成部分(token),这一过程就叫tokenize。例如,第一行就被拆成了package和main。
这个阶段,go就像小婴儿只会理解我、要、吃饭等词,但串不成合适句子。因为"吃饭我要"是讲不通的,所以把词按一定的语法串起来的过程就是lexical
anaylize或者parse,简单吧!和人脑不同的是,被程序理解的代码,通常会以abstract syntax
tree(AST)的形式存储起来,方便进行校验和查找。
Go的AST
那我们来看看go的ast库对代码的理解程度是不是小婴儿吧(可运行的源代码在此),其实就是token+parse刚才我们看到的上一章代码,并且按AST的方式打印出来,结果在这里
package main
import (
"go/ast"
"go/parser"
"go/token"
)
func main() {
// 这就是上一章的代码.
src := `
package main
func main() {
println("Hello, World!")
}
`
// Create the AST by parsing src.
fset := token.NewFileSet() // positions are relative to fset
f, err := parser.ParseFile(fset, "", src, 0)
if err != nil {
panic(err)
}
// Print the AST.
ast.Print(fset, f)
}
为了不吓到你,我先只打印前6行:
0 *ast.File {
1 . Package: 2:1
2 . Name: *ast.Ident {
3 . . NamePos: 2:9
4 . . Name: "main"
5 . }
// 省略之后的50+行
可见,go
解析出了package这个关键词在文本的第二行的第一个(2:1)。“main"也解析出来了,在第二行的第9个字符,但是go的解析器还给它安了一个叫法:ast.Ident,
标示符 或者大家常说的ID,如下图所示:
Ident +------------+
|
Package +-----+ |
v v
package main
接下来我们看看那个main函数被整成了什么样。
6 . Decls: []ast.Decl (len = 1) {
7 . . 0: *ast.FuncDecl {
8 . . . Name: *ast.Ident {
9 . . . . NamePos: 3:6
10 . . . . Name: "main"
11 . . . . Obj: *ast.Object {
12 . . . . . Kind: func
13 . . . . . Name: "main"
14 . . . . . Decl: *(obj @ 7)
此处func main被解析成ast.FuncDecl(function
declaration),而函数的参数(Params)和函数体(Body)自然也在这个FuncDecl中。Params对应的是*ast.FieldList,顾名思义就是项列表;而由大括号”{}“组成的函数体对应的是ast.BlockStmt(block
statement)。如果不清楚,可以参考下面的图:
FuncDecl.Params +----------+
|
FuncDecl.Name +--------+ |
v v
+----------------------> func main() {
| +->
FuncDecl ++ FuncDecl.Body +-+ println("Hello, World!")
| +->
+----------------------> }
而对于main函数的函数体中,我们可以看到调用了println函数,在ast中对应的是ExprStmt(Express
Statement),调用函数的表达式对应的是CallExpr(Call
Expression),调用的参数自然不能错过,因为参数只有字符串,所以go把它归为ast.BasicLis (a literal of basic
type)。如下图所示:
+-----+ ExprStmt +---------------+
| |
| CallExpr BasicLit |
| + + |
| v v |
+---> println("Hello, World!")<--+
还有什么?
50 . Scope: *ast.Scope {
51 . . Objects: map[string]*ast.Object (len = 1) {
52 . . . "main": *(obj @ 11)
53 . . }
54 . }
55 . Unresolved: []*ast.Ident (len = 1) {
56 . . 0: *(obj @ 29)
57 . }
58 }
我们可以看出ast还解析出了函数的作用域,以及作用域对应的对象。
小结
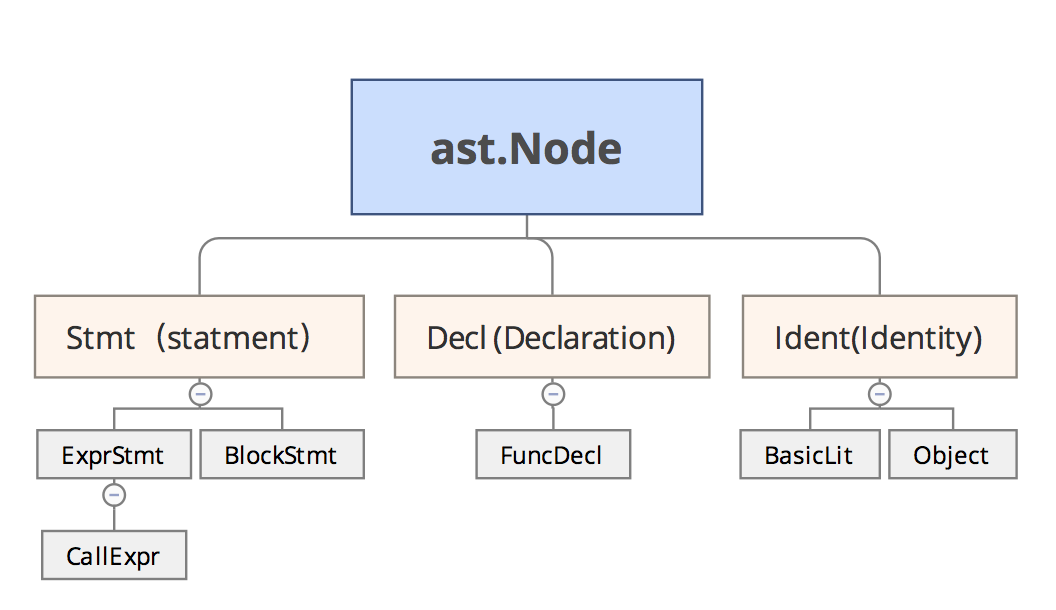
Go将所有可以识别的token抽象成Node,通过interface方式组织在一起,它们之间的关系如下图示意: