如果各位同学在coding过程中,需要打印变量,捕捉异常,但只能用print变量的方法解决问题,而你觉得不优雅,不方便,急需一种调试的方法的话,那这篇文章很适合你。
我学这些是因为在Django调试中,平时使用默认的Error
Page已经是非常方便了,但是,有次在对外API测试中可能会出现无法查看那个错误页的情况,两眼瞎,四处pirnt,最后还不能解决问题……如此屈辱后,我等痛下决心,一定找到更好的解决方法,因此有了本文。技巧
ipdb断点法[排错/尝试]
在你想打断点的地方,加上这句—-需要安装ipdb
import ipdb;ipdb.set_trace()
[ ](blog/wp-
](blog/wp-
content/uploads/2012/11/2012-11-17-213312的屏幕截图.png)
当程序运行到这里时,在启动服务器的console中将会弹出上面的提示符。这时就可以在这里像使用console编程时一样地随心所欲了~
顺便推荐几个好用的快捷键
| 按键 |
含义 |
| l |
line:查看指定行,例如l 31 |
| r |
return:执行到当前函数返回 |
| c |
continue:继续执行代码,直到下个断点 |
| whatis |
查询某个变量是什么 |
有了这招,基本的疑难杂症都可以debug掉了~
logger大法[定位/记录]
这是今天的主角,相对上面的方法,这个的自动化程度不是一般的高,在不改变源代码的情况下就可以记录所有的django行为。
在Django的settings.py里面,可以看到下面这自动添加的LOGGING这个设置变量。默认情况下,Django只会在DEBUG=False时,当服务器遭到500错误,才会发邮件给admins。而我们现在要在代码中加入一个logger,这样,任何错误或者是希望打印出来的信息都不会逃走啦~而且还可以自定义等级记录哦~
在settings.py中
from logging.handlers import SysLogHandler
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
"syslogHandler":{
"class":"logging.handlers.SysLogHandler",
"formatter":"verbose",
'address': '/dev/log',
"facility":SysLogHandler.LOG_LOCAL6
},
},
'loggers': {
"project":{
"handlers":["syslogHandler"],
"level":"DEBUG", #整个project的logger等级为DEBUG
},
"project.app":{
"handlers":["syslogHandler"],
"level":"INFO", #而project下的app对应的是INFO等级
},
},
"formatters":{
'verbose': {
'format': '%(levelname)-8s[%(name)s][%(funcName)s:%(lineno)d] %(message)s',
},
}
}
在某些你想记录log的地方
import logging
logger = logging.getLogger(__name__)
logger.error('This is an error')
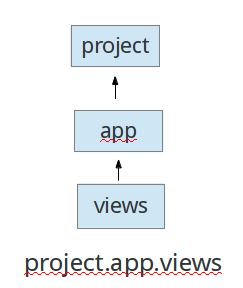
注意这个__name__,返回值是app+文件名,有利于我们定位bug和使用不同的handler,比如下面的传递路径示意:
[ ](blog/wp-
](blog/wp-
content/uploads/2012/11/2012-11-20-220942的屏幕截图.png)
如果一条log信息被project.app.views的handler抓住了,并且,propagate=False时,父级的handler,比如"project.app",就不会收到此log。
至于logger语句放在哪里,我个人习惯跟着try except这段,用于捕捉异常,或者在方法开始时logger.info查看相关参数。
而logger默认等级有6种:NONE, DEBUG, INFO, WARNING, ERROR, CRITICAL(严重等级由低到高)
至于logger输出目的地,有很多种选择,可以输出到文件,邮件,http请求,也可以输出到syslog中。本文的例子就是输出到syslog中。
至于syslog的配置,网上也有不少好的文章,这里就不说了 当然这些logger等级时会在%(levelname)这个变量中出现,而一般的tail -f
最多只是输出他们,并不能主观地区分他们。所以需要另一个工具进行等级的划分和关键词的渲染(syntax
highlighting)。这里就严重推荐grcat这个小工具,能正则匹配,关键字各种格式化。
grcat的配置也十分简单,也有很多样例,网上可以搜到的。这里也不多说啦~ 讲错的地方,欢迎拍砖
](https://mzh.io/2012/12/2012-12-16-145748%E7%9A%84%E5%B1%8F%E5%B9%95%E6%88%AA%E5%9B%BE.png){kind=link}