最近逛Cloudflare的博客,发现已经有ARM64的服务器《Arm takes wing》,
文章里还吐槽了Go对于Arm64的优化不够好,特别是memmove这类的函数,实现方式没有优化过,而Go的内置copy函数,
slice的扩容时,背后都是runtime/memmove函数,因此说memmove的性能提升可以带来整个runtime的性能提升也不为过。
啥是memmove?
memmove是memory move的简写,说白了就是把内存中一个区域的数据,搬到另一个地方去。
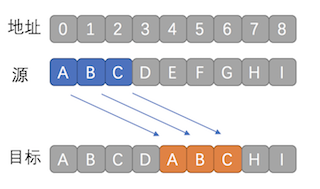
如图所示。
但是memmove需要应对另一种情况,那就是overlapping(内存重叠)即源地址+要移动的数量跟目标地址的起点有重叠。
如下图
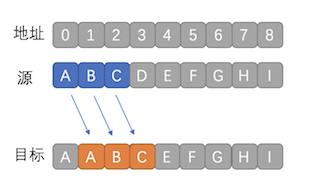
复制完A之后,图中位置1的数据就被改写成了A了,而不是我们预想的B
这样复制的结果就是AAA,明显是错误的结果。
那么怎么才能解决这个问题呢,那就是backward copy(后向复制)
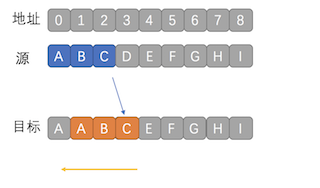
首先从内存位置2开始复制C到目标地址,依次向后(减少)复制数据,从而解决重叠导致的数据错误。
听起来很简单吧?
那我们就来动手吧!!!
实战方法一:简单字节移动
- 判断是否有重叠
- 按方向移动
核心代码如下:
ADD count, src, srcend
loop:
MOVB.P (src), tmp
MOVB.P tmp, (dst)
CMP src, srcend
BNE loop
这就是最简单的memmove了。
其中:
- ADD 加法操作, 两个寄存器内容相加,放到第三个寄存器中
- MOVB (move byte) 移动一个字节
- MOVB.P (move byte post-index) 移动完成_后_,对应寄存器 +1
- BNE (Branch Not Equal)两值不相等时,移动到对应标签上
还有很多指令,都可以在Arm的手册中查询到,Go自己实现了编译器,因此指令可能对不上,如果接下来有对不上的指令,我会指出来的。
代码写完后就是跑测试,测试不通时
使用gdb debug Go
$GODEV/bin/go test -c
gdb <文件名>
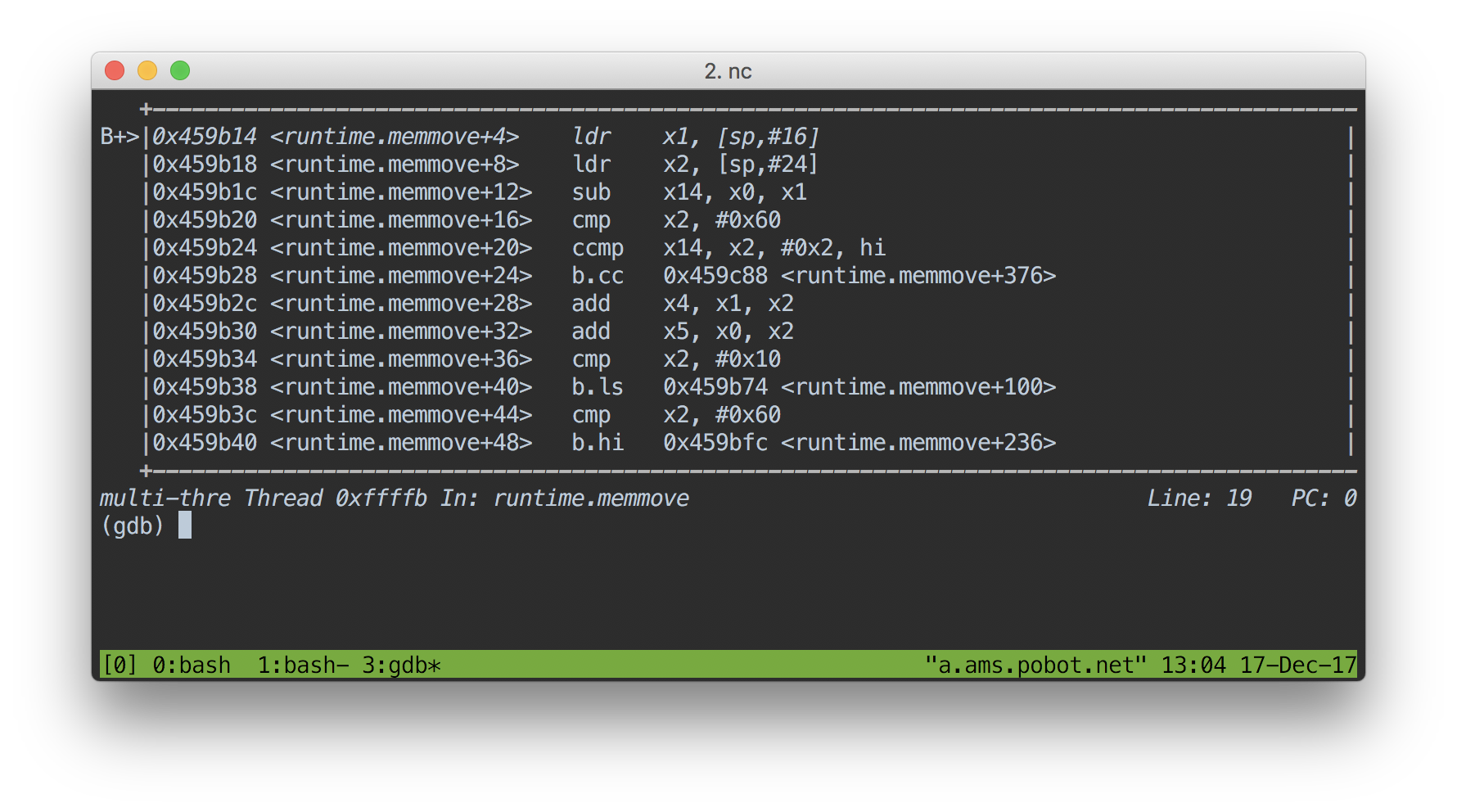
即可进入gdb,其中有以下常见的命令
b 文件名:行号 // break 设置断点
n // next 下一指令
layout asm // 设置输出汇编模式
c // continue 继续到下个断点
实战方法二: 多重移动
通过之前的例子,相信你也会开始想,一次只搬一个字节太慢了,能不能一次性搬多个?
这也是现在标准库的实现方式。
因为Arm64是64位平台,每次都可以操作8个字节,如果使用了MOVD指令(move double word)。一次性能移动8个字节了!
核心代码如下:
forwardlargeloop:
MOVD.P 8(R4), R8 // R8 is just a scratch register
MOVD.P R8, 8(R3)
CMP R3, R9
BNE forwardlargeloop

有!LDP/STP(Load/Store Data by Pair),这样可以一次移动16个字节。
LDP (R1), (R4, R5) //R1 为地址指针,移动数据至R4, R5
STP (R4, R5) ,(R0) // 移动R4, R5数据至 R0 为地址指针的区域
真有!VLD1/VST1(Load/Store Data to Vector),可以将内存载入向量寄存器V0-V3,每个寄存器有128bit。即一条指令可以移动多达64个字节!
VLD1.P 64(R1), [V0.B16, V1.B16, V2.B16, V3.B16]
VST1.P [V0.B16, V1.B16, V2.B16, V3.B16], 64(R0)
但是,测试性能的话,你会发现,还不如LDP快。
坑1: 并不是那么快的SIMD (slow simd on Arm)
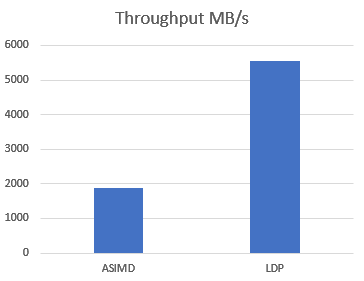
测试代码 https://gist.github.com/mengzhuo/bb3769d42097eec6f3fce12895e441b9
主要是因为,ARM架构中,ASIMD作为协处理器,虽然在软件优化手册中,延迟只有5个微指令,但是每次写都会阻塞流水线(需要等待数据写入)。例子有很多,所以性能要求高的实现(glibc、Linux kernel、Chrome)都没有选择用ASIMD作为Memmove/Memcpy的指令基础。
实战方法三: 指令展开(unroll instructions)
既然有这么库实现了ARM64的memmove,我们自然会参看一下
例如Linux的memmove
.Lcpy_over64:
subs count, count, #128
b.ge .Lcpy_body_large
/*
* Less than 128 bytes to copy, so handle 64 here and then jump
* to the tail.
*/
ldp1 A_l, A_h, src, #16
stp1 A_l, A_h, dst, #16
ldp1 B_l, B_h, src, #16
ldp1 C_l, C_h, src, #16
stp1 B_l, B_h, dst, #16
stp1 C_l, C_h, dst, #16
ldp1 D_l, D_h, src, #16
stp1 D_l, D_h, dst, #16
tst count, #0x3f
b.ne .Ltail63
b .Lexitfunc
你会发现,都是整16,32,64字节的移动,很少像我们上个例子中移动16字节后,减去位移数并判断一下是否需要返回。
这种优化称做指令展开(unroll instructions),主要为了减少条件跳转语句的执行,毕竟每个指令的执行都会消耗CPU时间。
坑2: 分支预测失效 (branch misprediction)
就算不考虑跳转指令导致的CPU消耗,还有分支预测失效(branch misprediction)的风险,一旦预测失效,CPU会消耗13微指令的时间来清空流水线,并重新执行(手册5.1z章)
With Program flow prediction enabled, all mispredicted branches incur a 13-cycle penalty
相比之下,一个LDP指令只需要4个微指令时间,意味着一次预测失败就要少搬48个字节。
实战方法四: 优雅的覆盖
通过上面的例子,你会发现其实对于小数据移动,我们可能压根不需要循环遍历,只需要找足够的寄存器,把源地址的所有数据全部载入到寄存器中,然后再依次放入目标地址中就好了。
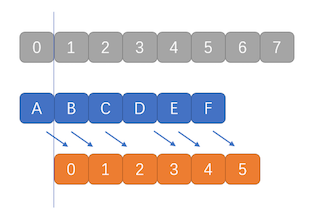
例如上图,移动长度是6,源地址为0-5,目标地址是1-6。
移动指令只能移动1,2,4,8字节,没有6的怎么办?那么我们就用移动4个字节的MOVH( move half word )。
如下图所示,先用R4保存0-3的数据,再用R5保存2-5的数据
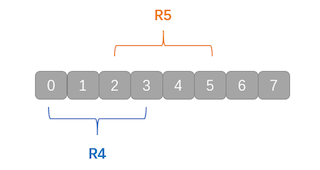
这样的话R4,R5都保存了2、3上的数据,虽然2-3重叠的部分会被覆盖掉,但是数据是完全一致的。完美地解决了重叠的问题。
移动后数据如下图所示。
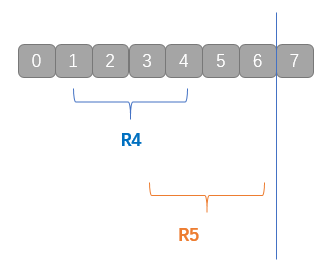
代码如下
ADD count, src, srcend
ADD count, dst, dstend
MOVH (src), R4
MOVH -4(srcend), R5
MOVH R4, (dst)
MOVH R5, -4(dstend)
这就是glibc的memcpy.S的原理,同时也促成了Go CL83175: runtime: improve arm64 memmove
经过这多么优化,我们来测试一下性能增长的情况,下图是字节数移动的性能报告,数值越大性能增幅就越大。
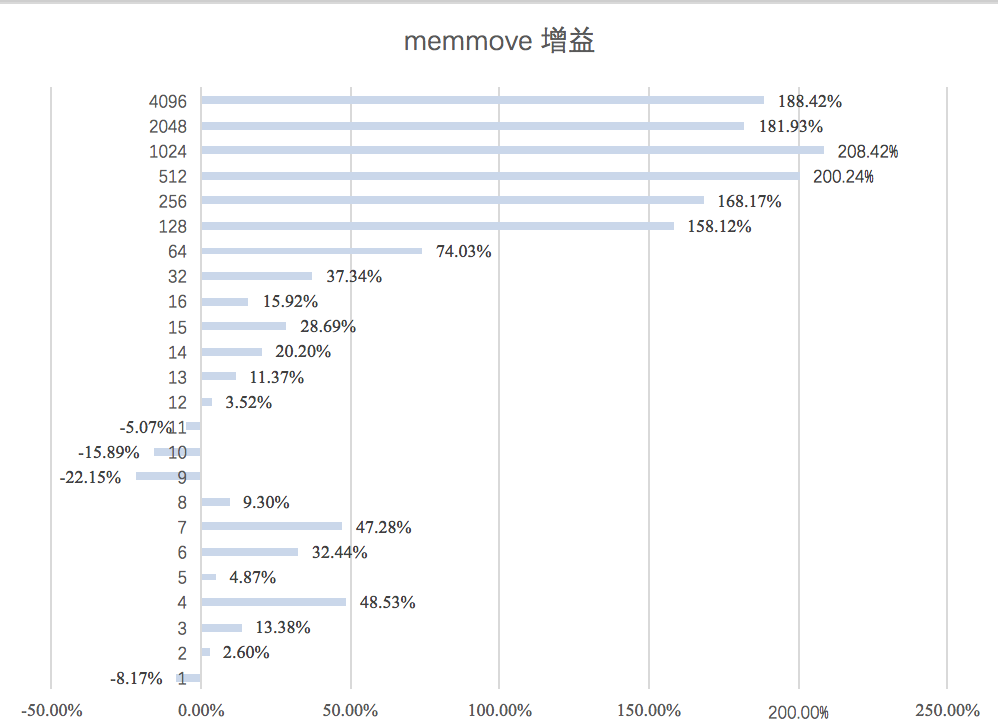
咦……为啥移动9-11个字节时的性能不升反降?!
坑3: 未对齐数据访问性能下降(unaligned data access penalty)
什么是未对齐?
计算机由于性能的考虑,通常在取内存时是以特定数量一次性地取走的,例如一次取4个字节。
当你只取3个字节,或者任意不是4为倍数的地址的时候,就叫做未对齐数据访问。这时CPU都要先找到对应的4字节位置并取出来,然后再取到对应的3个字节并会造成此类性能下降。
Linux Kernel中也有详细的解释。
但是根据ARM的优化手册( 4.6 P39)
Load/Store Alignment
The ARMv8-A architecture allows many types of load and store accesses to be arbitrarily aligned.
The Cortex- A57 processor handles most unaligned accesses without performance penalties.
However, there are cases which reduce bandwidth or incur additional latency, as described below.• Load operations that cross a cache-line (64-byte) boundary
• Store operations that cross a 16-byte boundary
手册上说是几乎不会下降的……蛤?

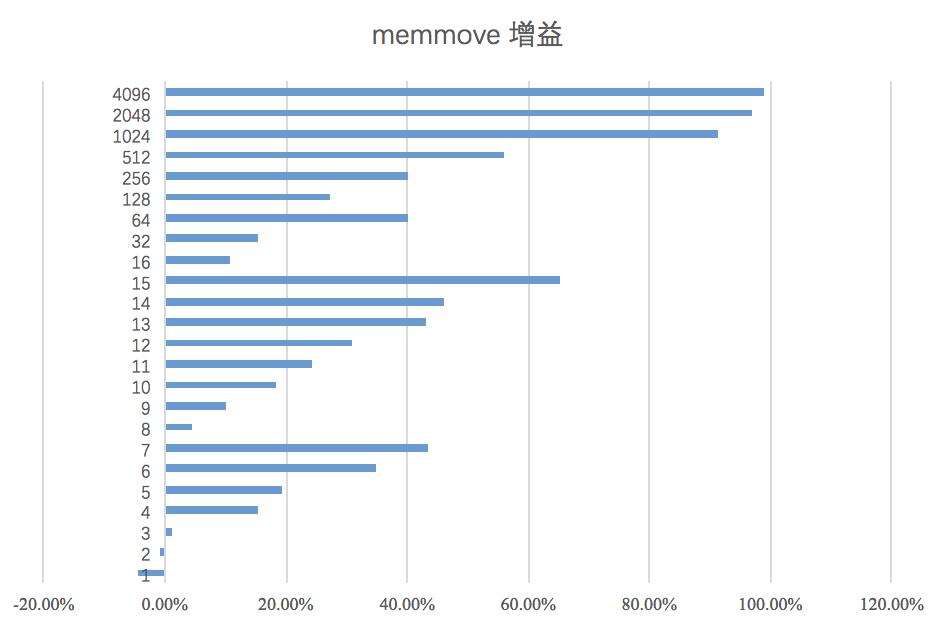
最后通过测试发现,原来是CPU的区别,Makam的测试报告显示(如下图),还在技术评审的AmberWing CPU在测试中并没有下降。
而因为我测试用的2010年的Marvell Armada XP,比较老,所以可能并没有对未对齐优化。
小结
总结一下,这次的优化最高可以给Go Arm64平台的memmove带来100%的性能提升,平均也有34%。